Key milestones
Key drivers of recent progress in neural networks
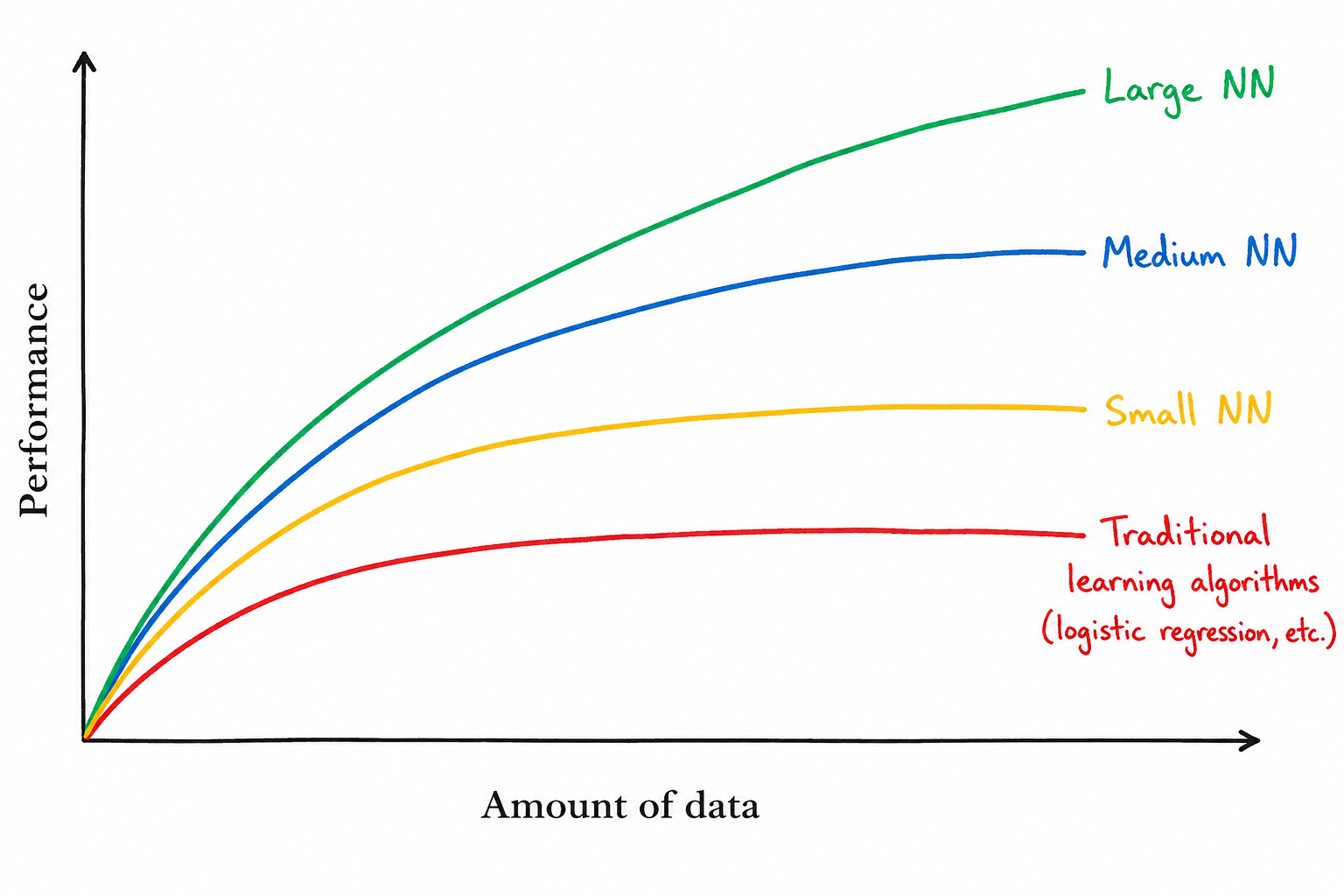
Availability of large-scale datasets
Increasing computational power (especially GPUs/TPUs)
Advances in algorithms and neural network architectures
Specialization of neural networks:
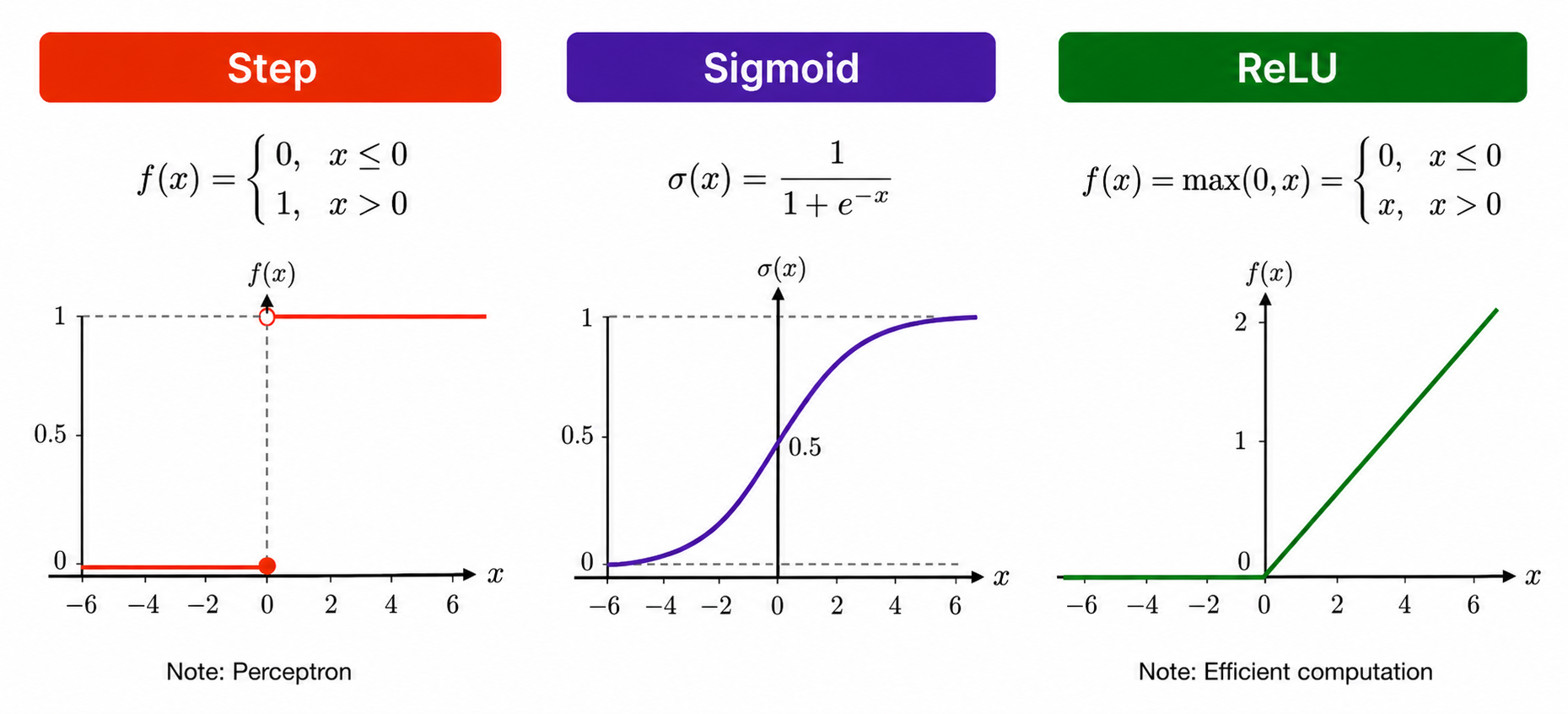
A perceptron is one of the earliest forms of neural networks. A classical perceptron is characterized by:
\[z = w^T x + b\]
followed by a threshold activation:
\[\hat{y} = \begin{cases} 1 & \text{if } w^T x + b > 0 \\ 0 & \text{otherwise} \end{cases}\]
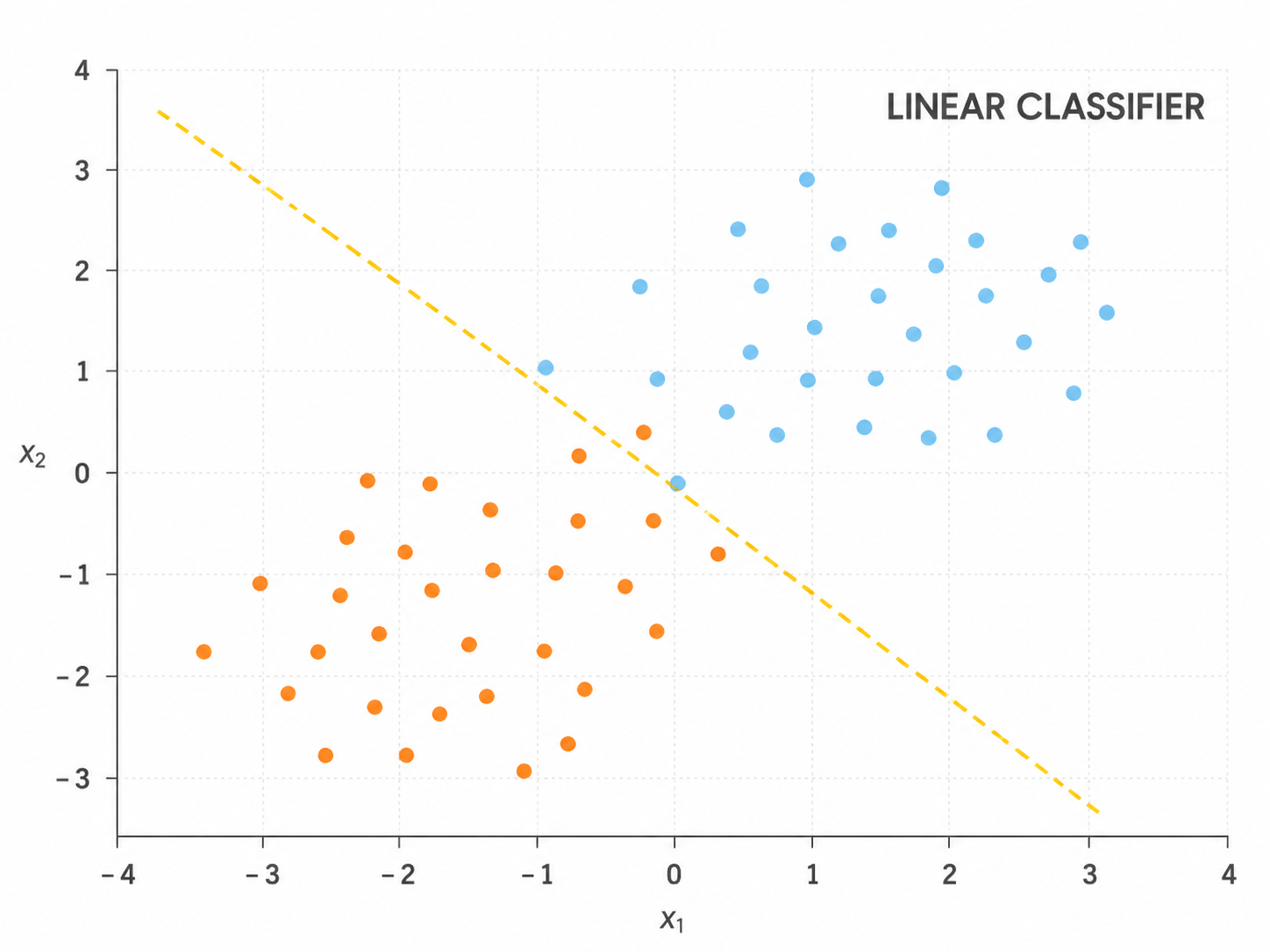
Limitation of a single perceptron: It cannot build abstract intermediate representations and can only learn linear decision boundaries.
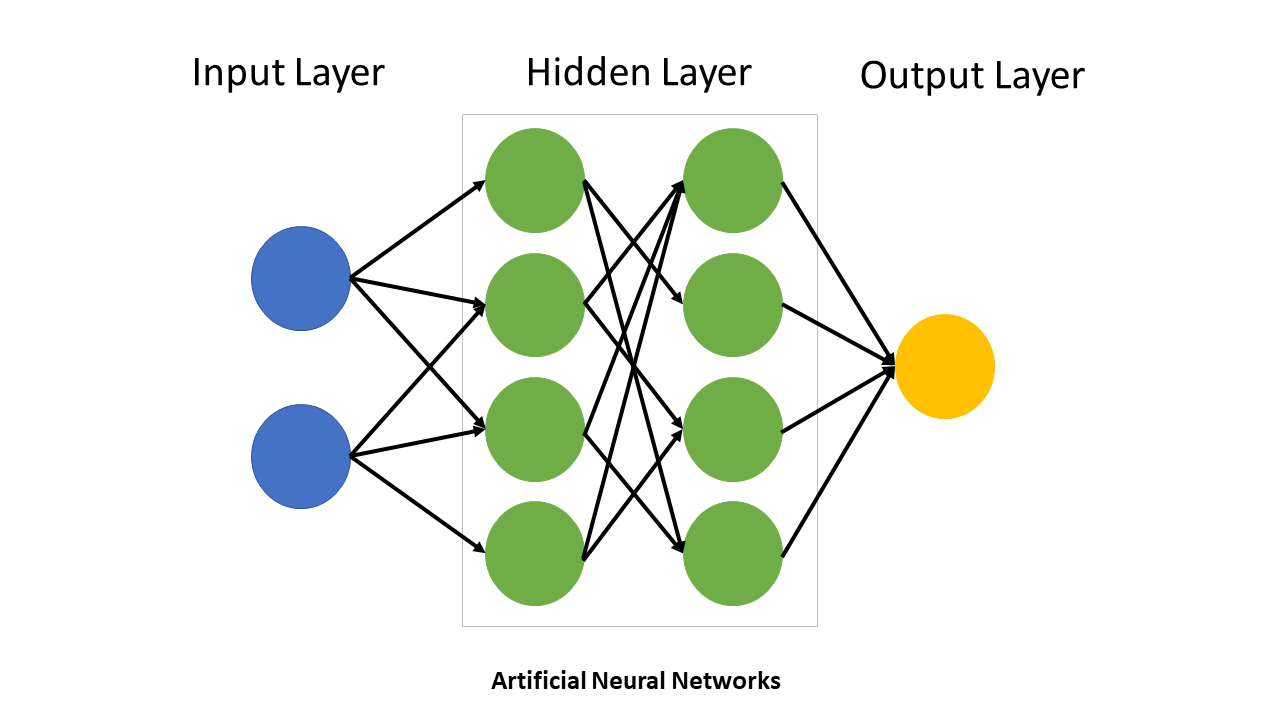
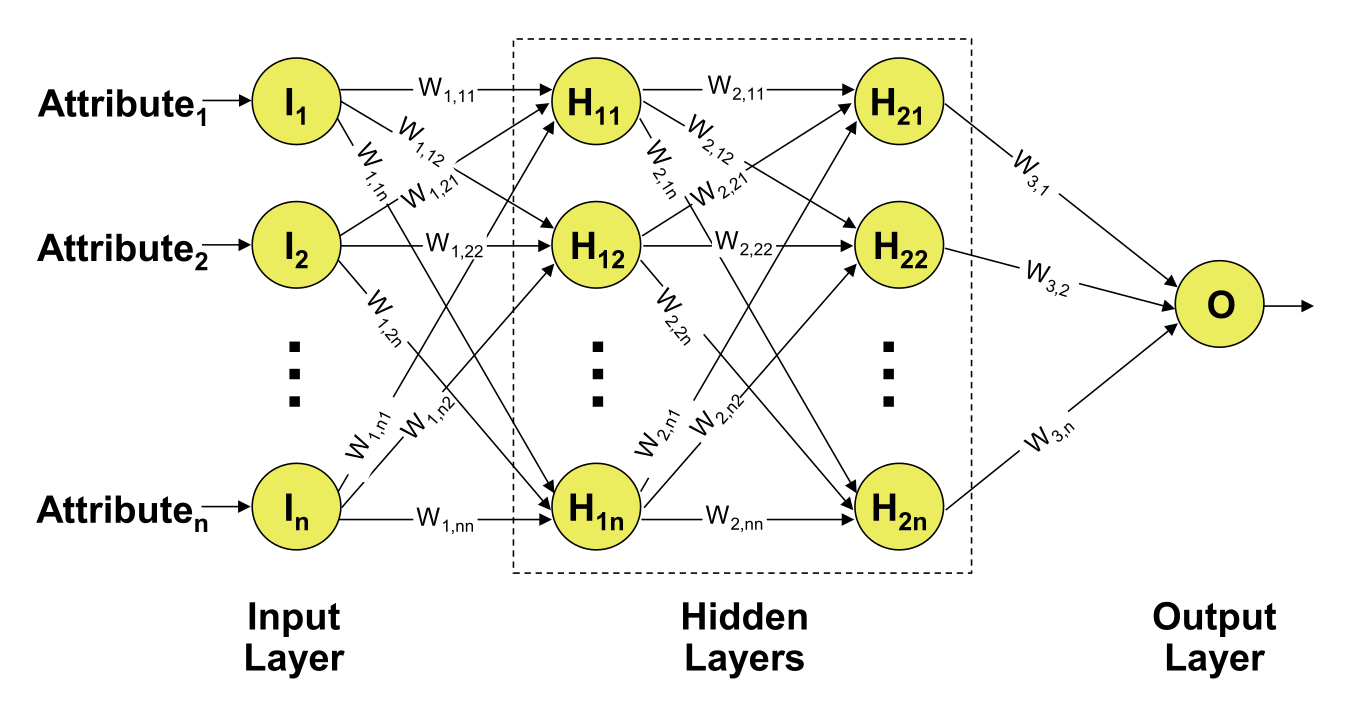
Solution: Multilayer neural networks combine:
Layers:
Note: the number of layers and neurons is specified ex-ante and does not change in the training process.
🎥 Grant Anderson (3Blue1Brown) provides a series of instructive
animated explanations, including one on Neural Networks.
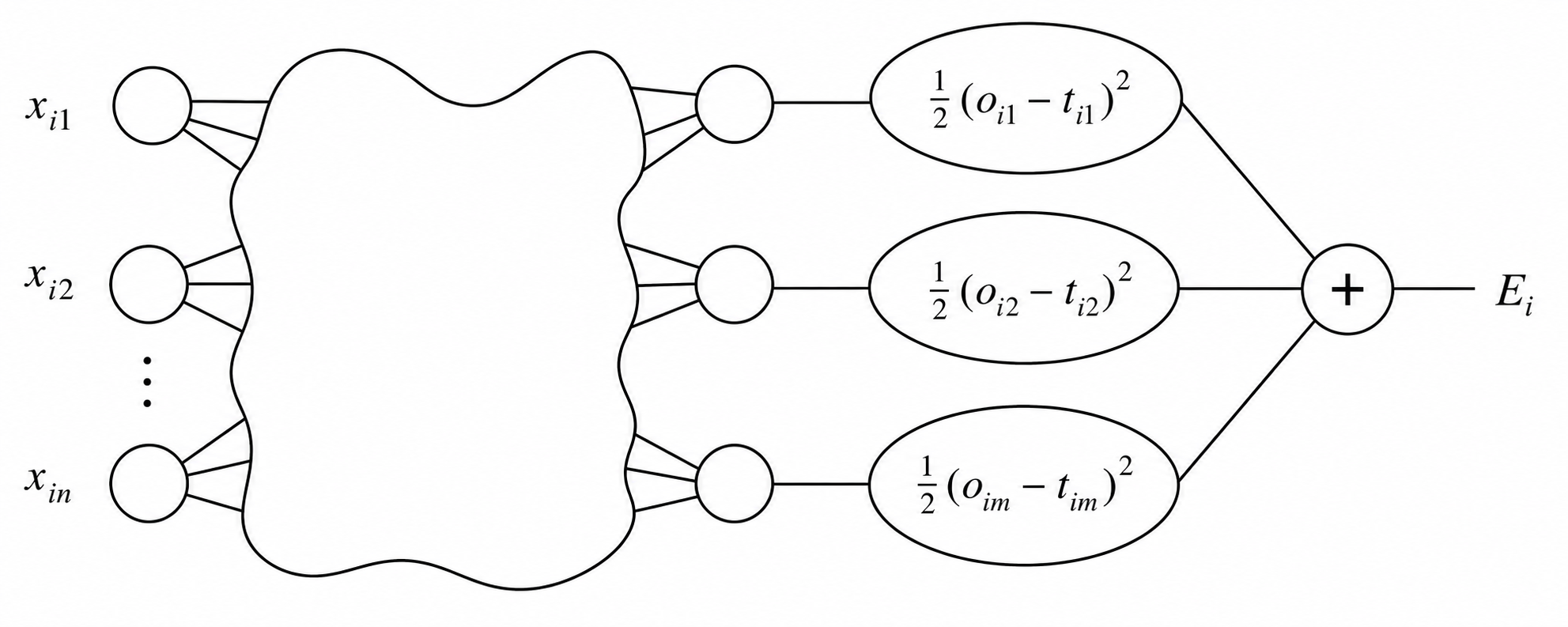
The network’s prediction error is measured with a loss function.
For one training example \(i\):
\[E_i = \frac{1}{2} \sum_{j=1}^{m} (o_{ij} - t_{ij})^2\]
This is the squared error loss across all output neurons \(j\).
Across all \(h\) training examples, the total loss is:
\[E = \sum_{i=1}^{h} E_i\]
Backpropagation adjusts the weights to reduce this total loss.
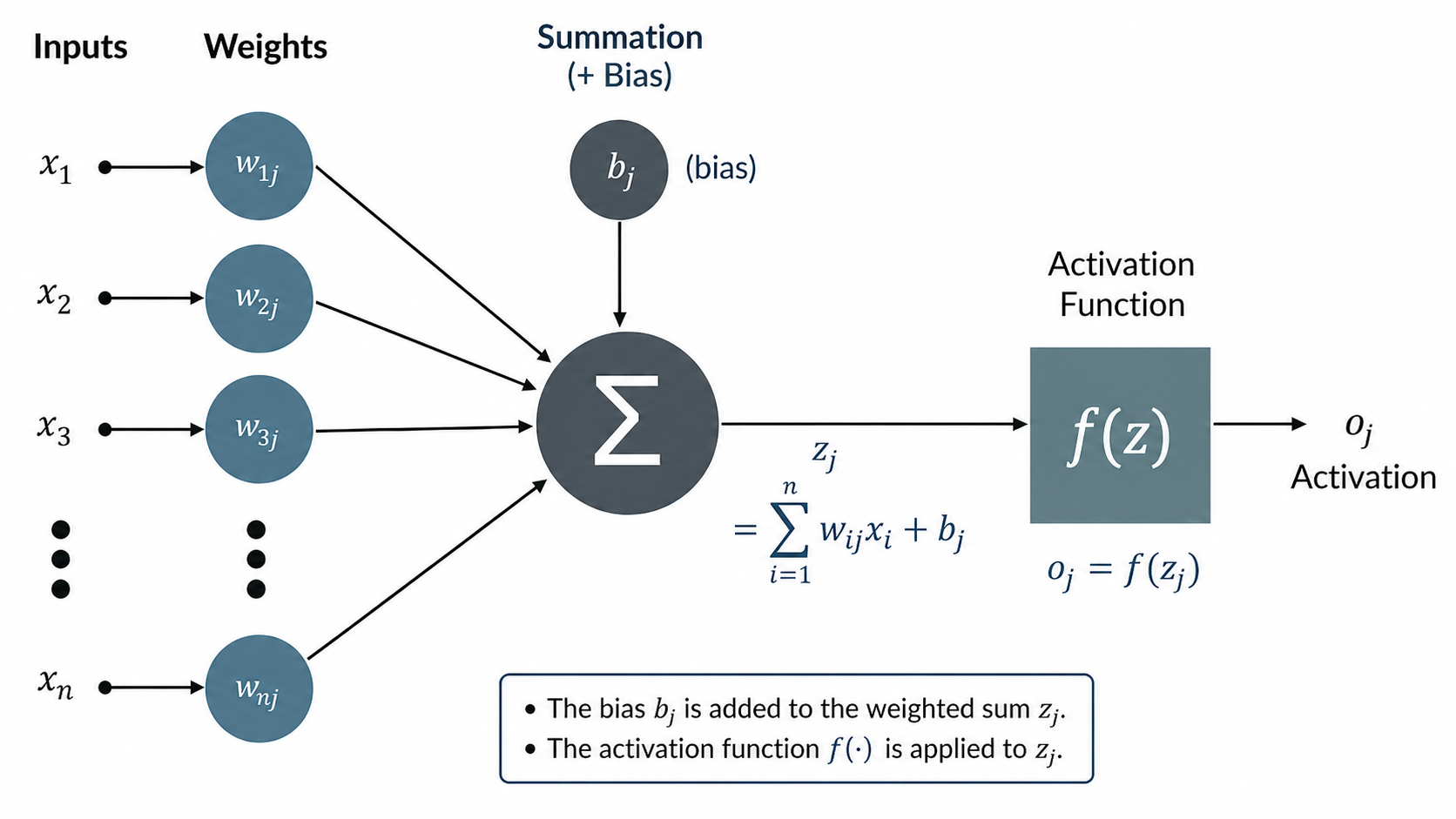
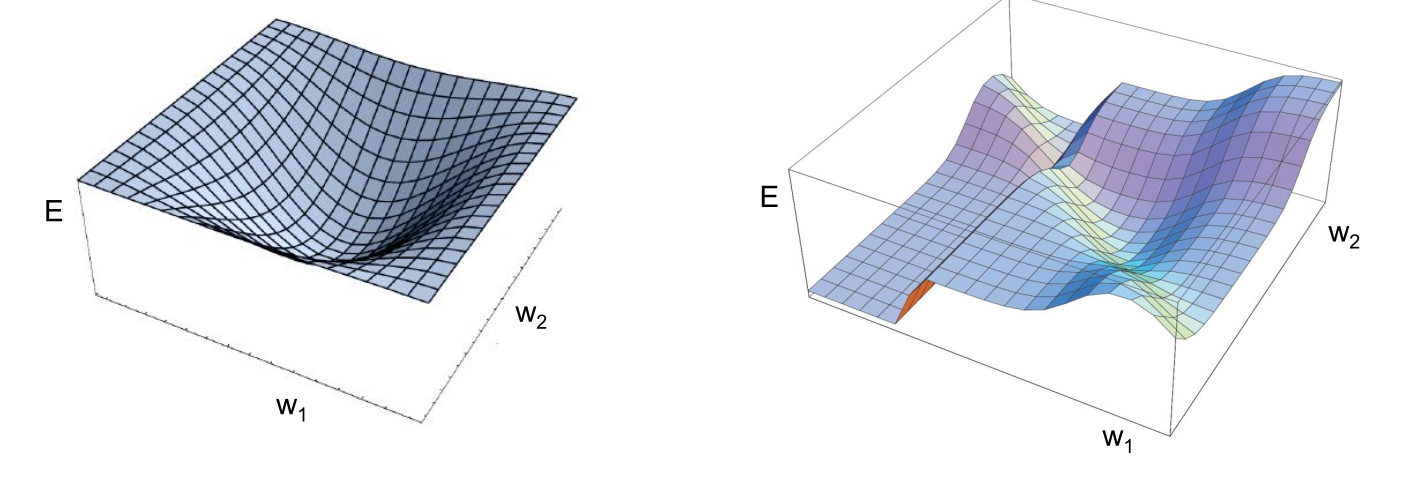
The loss function \(E\) has to be minimized. Because it depends on the output neurons \(o_j\), it automatically depends on their weights to the precedent layer(s):
\[o_j=f(s(x)_j) \text{ with } s(x)_j =\sum_k^n w_{jk}\cdot x_k\]
Thus, the weights have to be found where \(E\) is minimal.
Examples of the loss function with two weights (simplified):
Basic neural networks are often introduced as fully connected feed-forward networks. Specialized architectures go beyond this and differ in the following design choices:
| Design choice | How architectures differ |
|---|---|
| Input structure assumed | Different architectures are built for different data structures, such as tabular data (MLPs), spatial data and images (CNNs), sequence data (RNNs or Transformers), relational data (graph neural networks), or ; generative tasks (GANs). |
| Neuron / unit type | The basic unit may be a dense neuron, recurrent cell, gated LSTM/GRU cell, attention head, or a generator/discriminator module. |
| Layer operation | Layers may perform matrix multiplication, convolution with moving filters, recurrent state updates, self-attention, or adversarial generator/discriminator training. |
| Connectivity pattern | Information may flow through all-to-all dense connections, local sliding windows, temporal loops with hidden states, or token-to-token attention. |
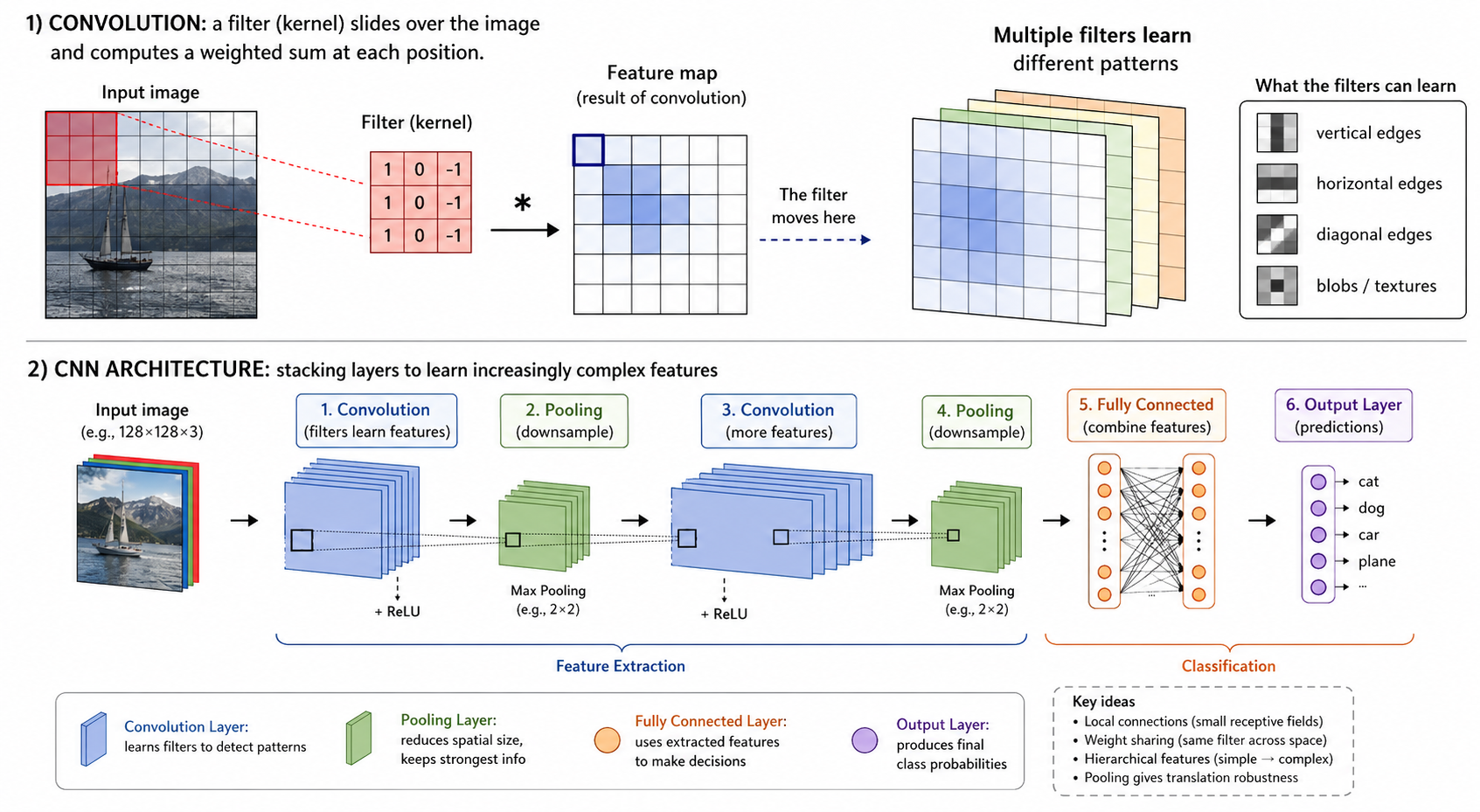
Focus in this section: We use CNNs, RNNs, and Transformers as key examples because they show three central architectural ideas:
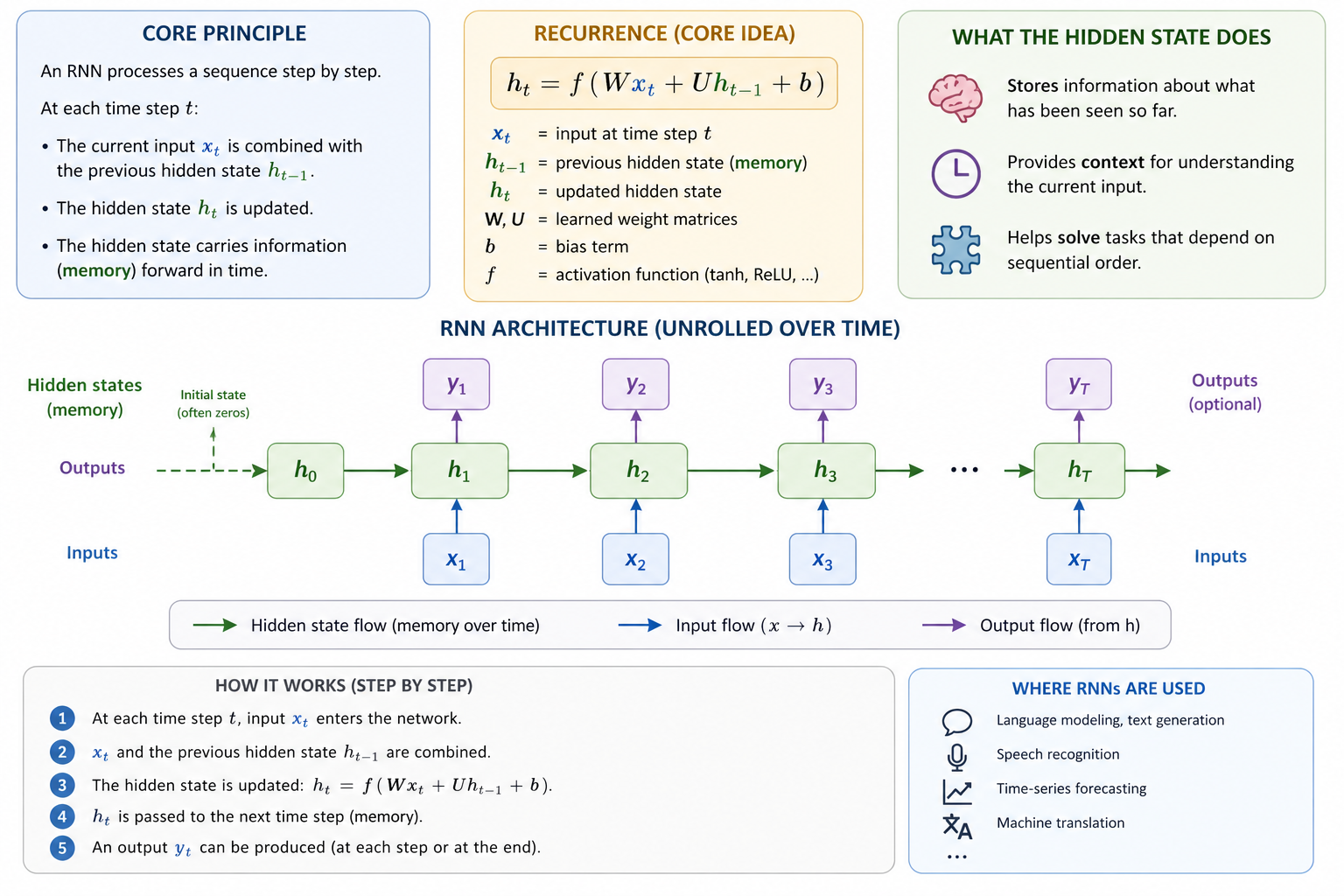
![]()
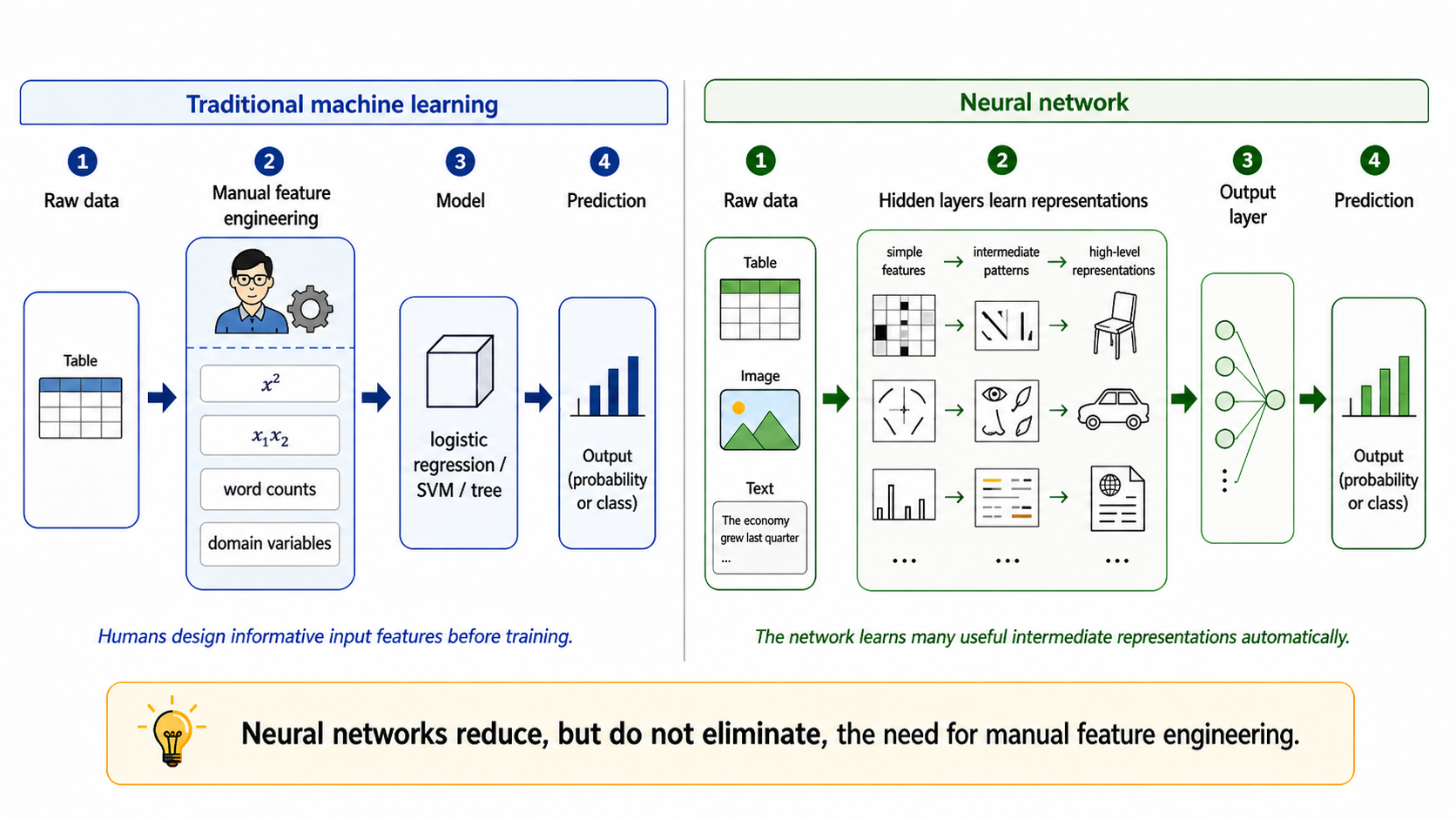
Traditional machine learning often relies strongly on manual feature engineering: humans design useful input variables before training the model. Neural networks can reduce this need because hidden layers learn intermediate representations from data. However, feature engineering does not disappear. We still need to decide: