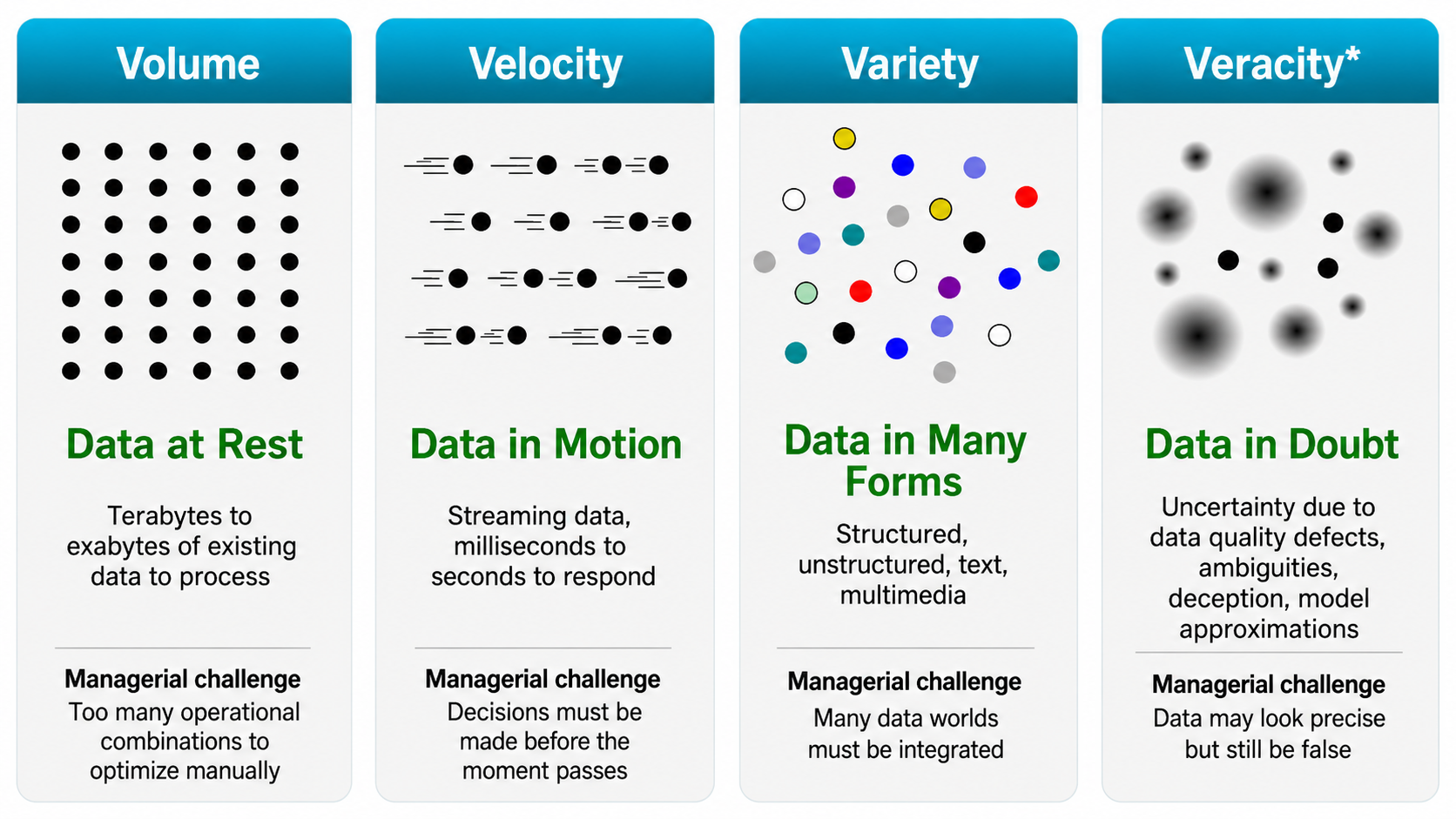
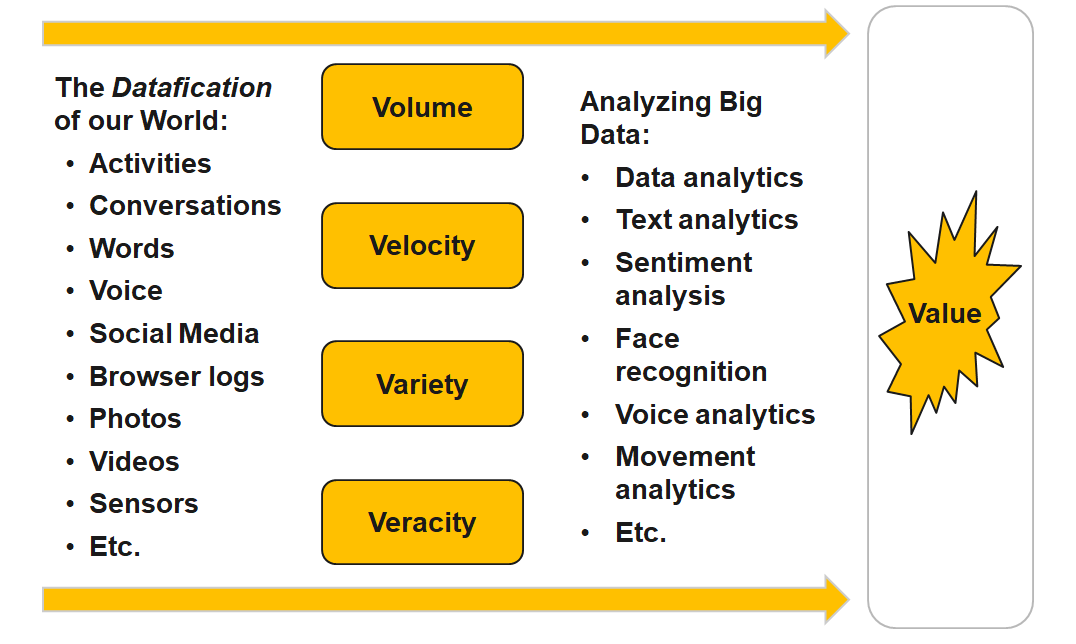
['gas' 'jupiter' 'largest' 'planet']Big data matters when the properties of the data change what managers can decide, automate, or compete on.
Managerial dilemma
How do you optimize millions of delivery decisions when every route has thousands of possible variants?
Key data facts
Models: vehicle routing · scheduling · ETA prediction · dynamic re-optimization
Outcomes: fewer miles · lower fuel costs · better on-time delivery · operational data advantage

Managerial dilemma
Can fraud be detected before the transaction is approved?
Key data facts
Models: real-time risk scoring · anomaly detection · streaming ML · network analysis
Outcomes: approve · decline · challenge · escalate — all within milliseconds

Managerial dilemma
How do you coordinate inventory when the relevant data comes from many different worlds?
Key data facts
Models: sensor fusion · demand forecasting · replenishment optimization · exception detection
Outcomes: fewer stockouts · fresher products · less waste · tighter supplier coordination

Managerial dilemma
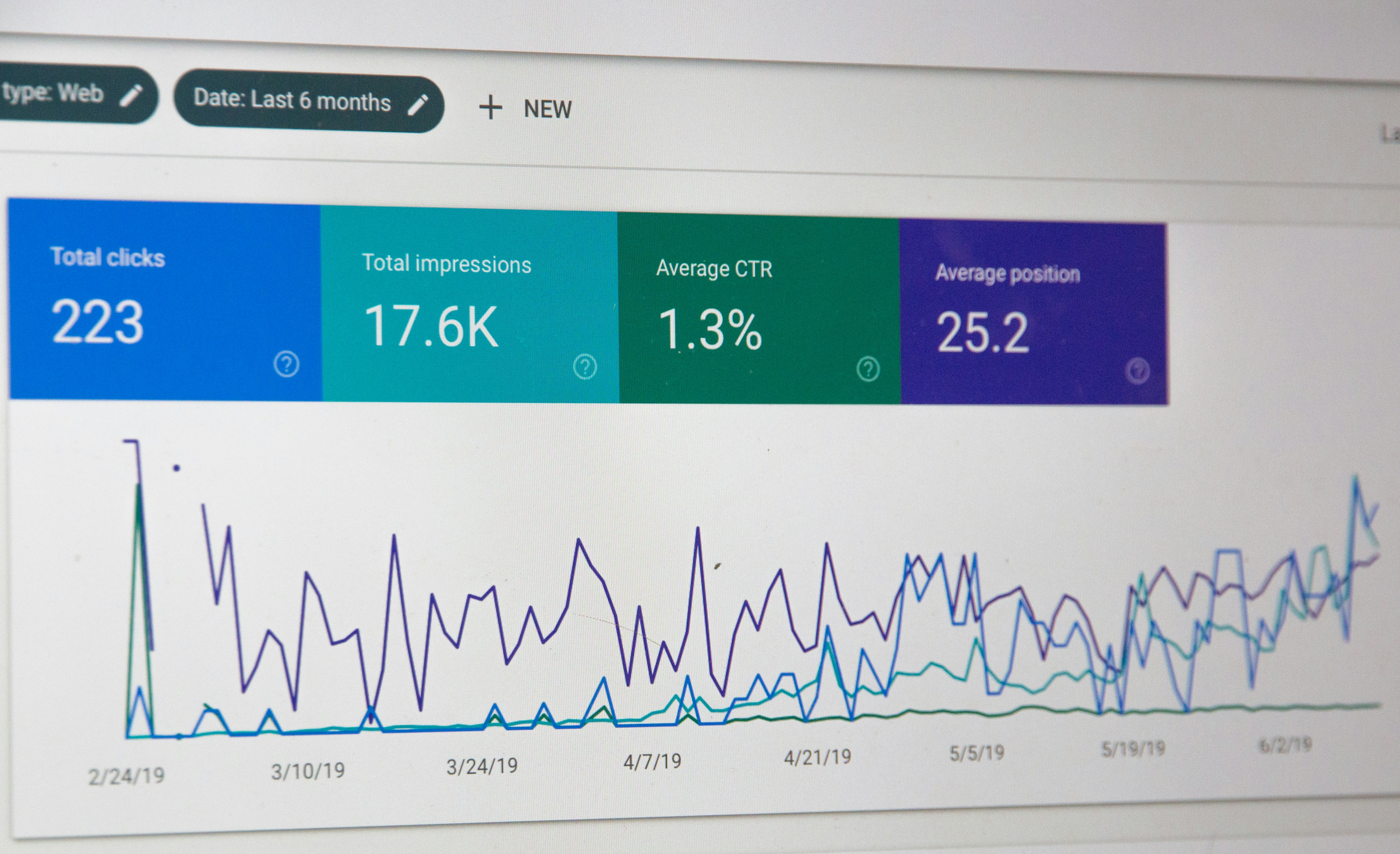
The dashboard says there were clicks and impressions — but were they real?
Key data facts
Models: bot detection · invalid traffic scoring · anomaly detection · graph analysis
Outcomes: block fake traffic · clean attribution · reallocate spend · protect ROI
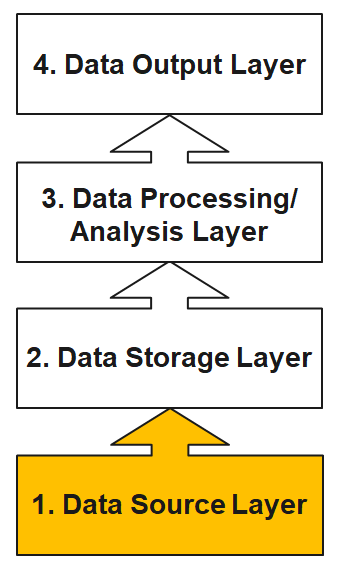
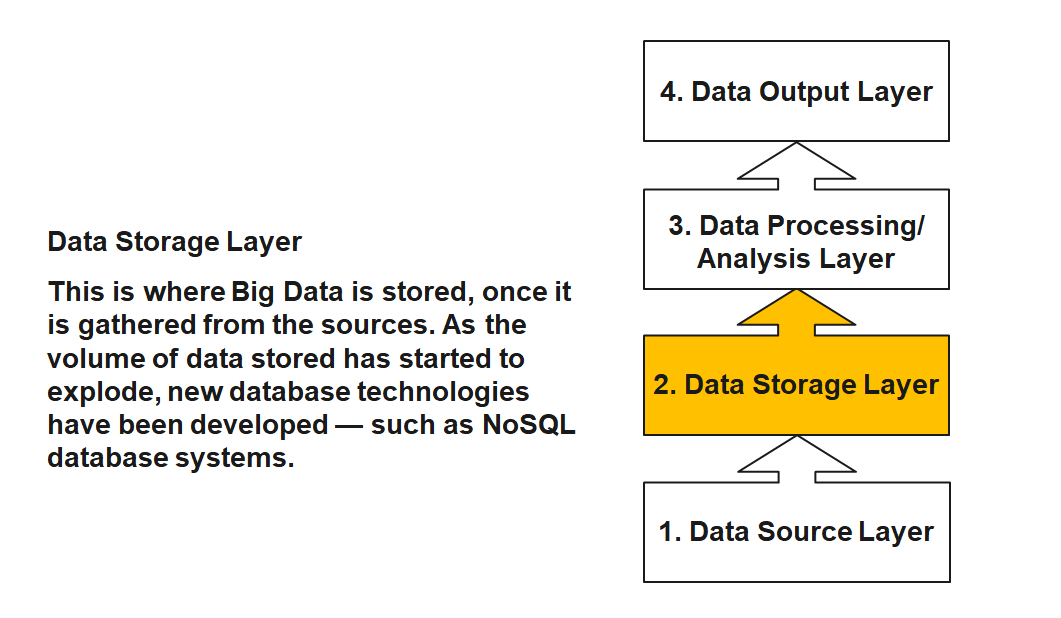
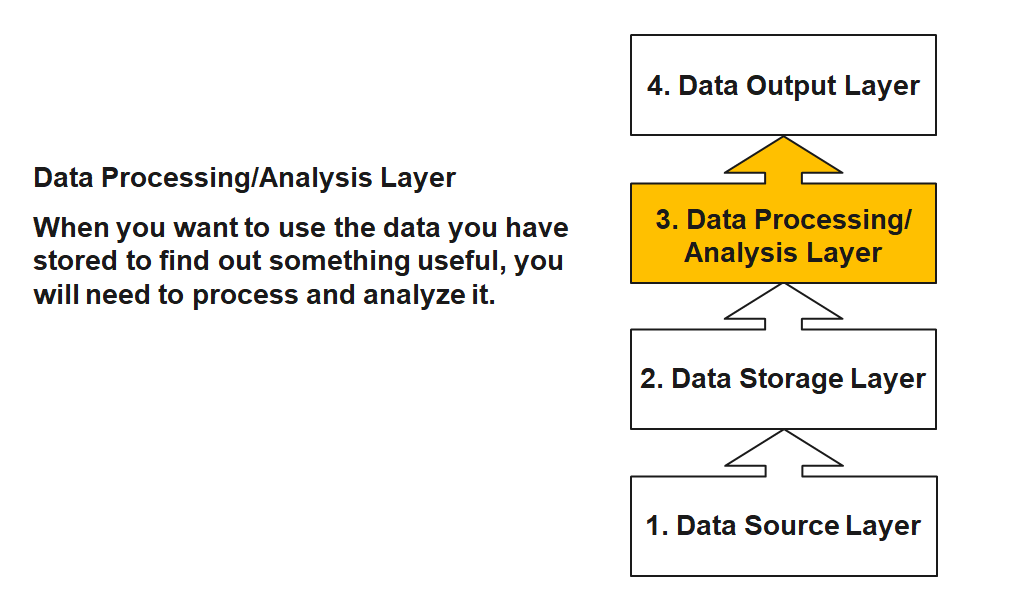
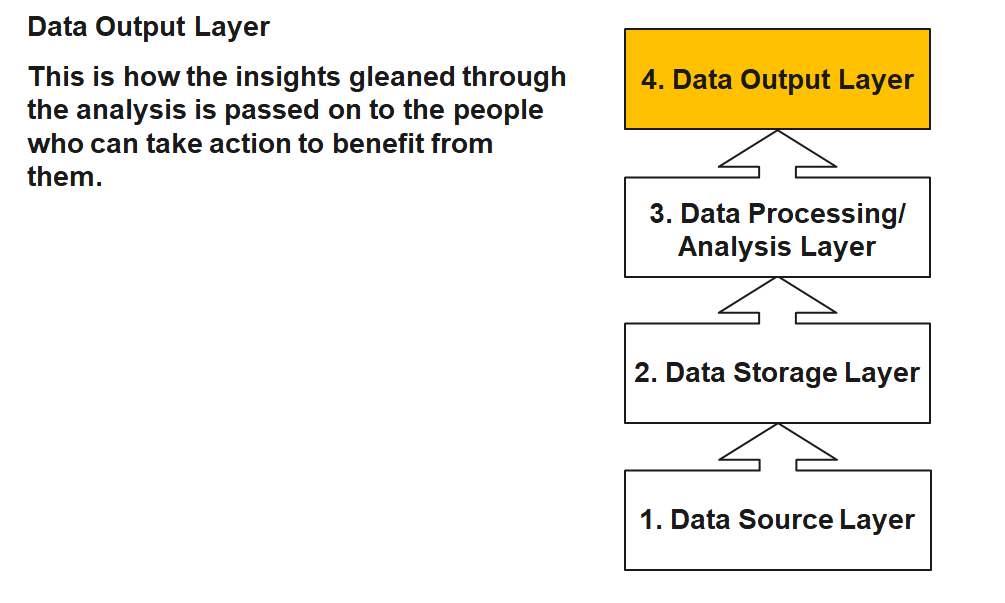
Data Source Layer
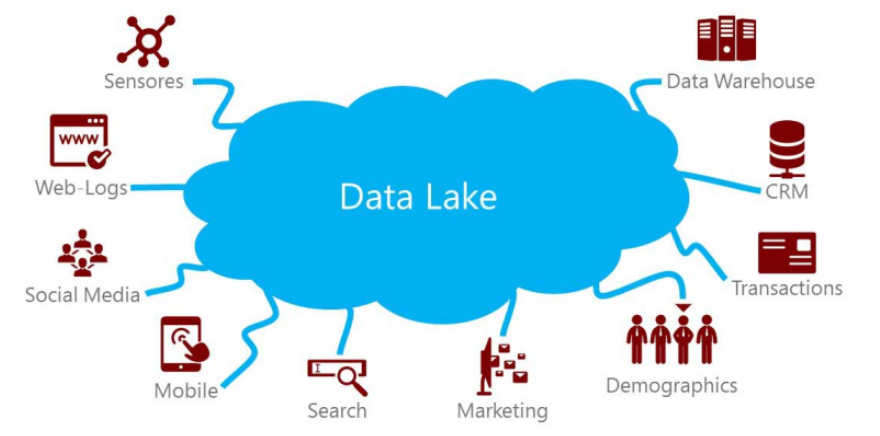
This is where the data arrives at the organization. It includes everything from sales records, customer database, feedback, social media channels, marketing list, email archives etc.
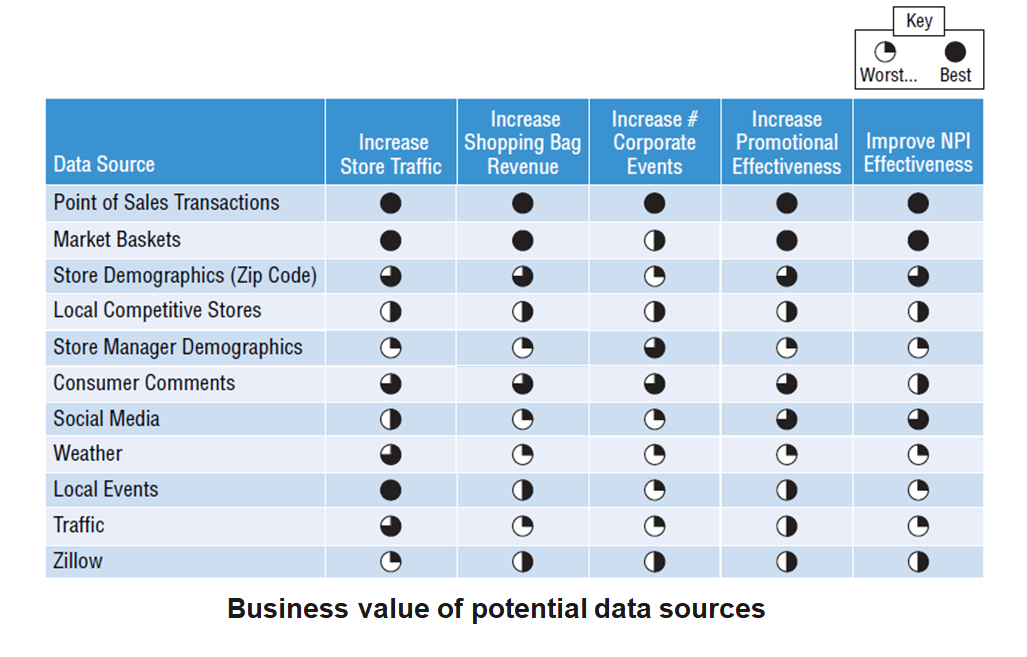
A data lake is a method of storing data within a system in its natural format, that facilitates the collocation of data in various schemata and structural forms. The idea of data lake is to have a single store of all data in the enterprise ranging from raw data to transformed data which is used for various tasks including reporting, visualization, analytics and machine learning.
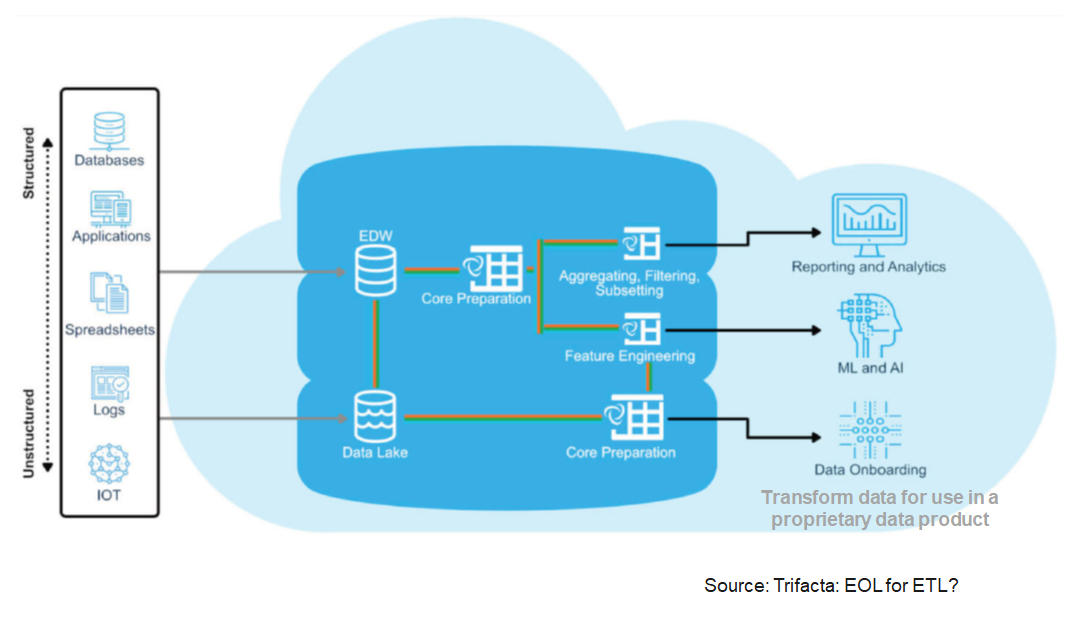
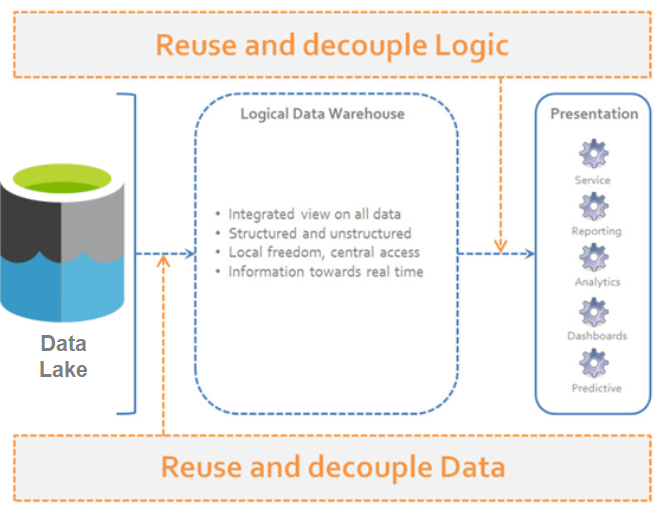
A “logical data warehouse” provides analytical company data without first physically moving it to a physical data warehouse.
As in a classic data warehouse, uniform views are provided for analysis purposes.
While the data in the classic data warehouse comes from a “well-defined” physically uniform database, the “logical data warehouse” pulls data together from the data lake at the time of the query.
Aggregation is done just in time. Thus, the schema of the data warehouse is just virtual.
The vast majority of global data is stored in unstructured formats. For example:
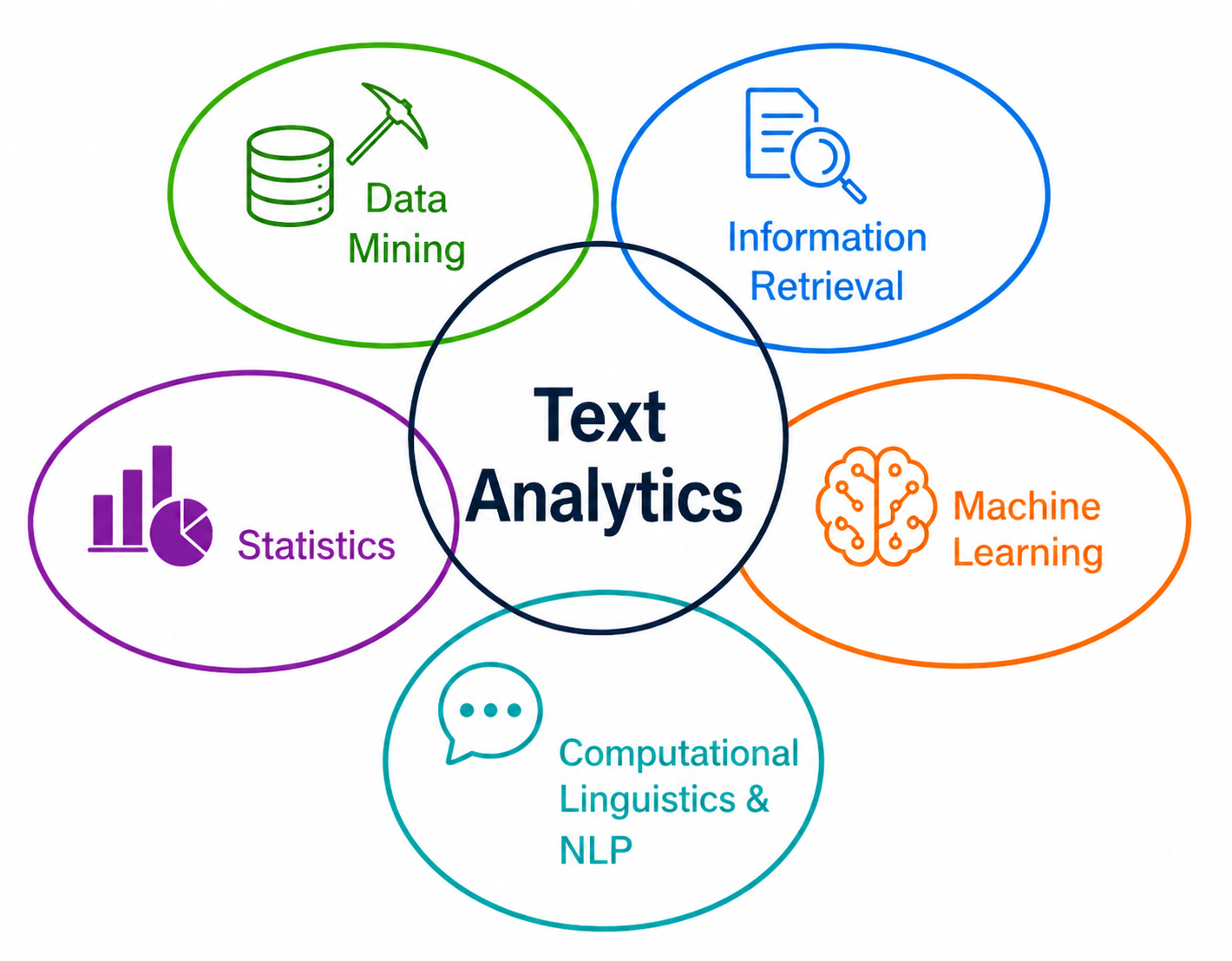
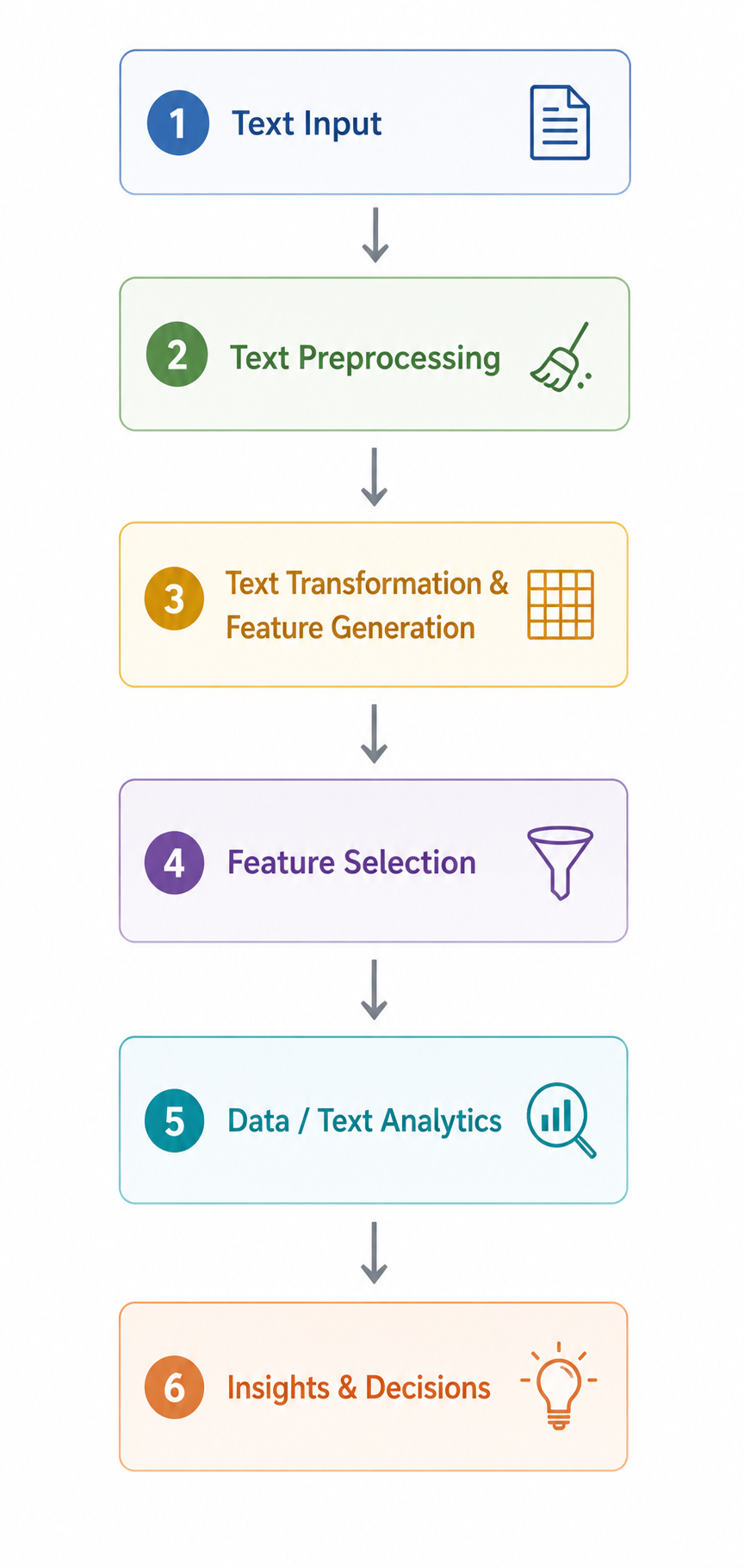
Text analytics combines methods from natural language processing, machine learning, information retrieval, and statistics to systematically analyze large volumes of textual data and derive actionable insights.
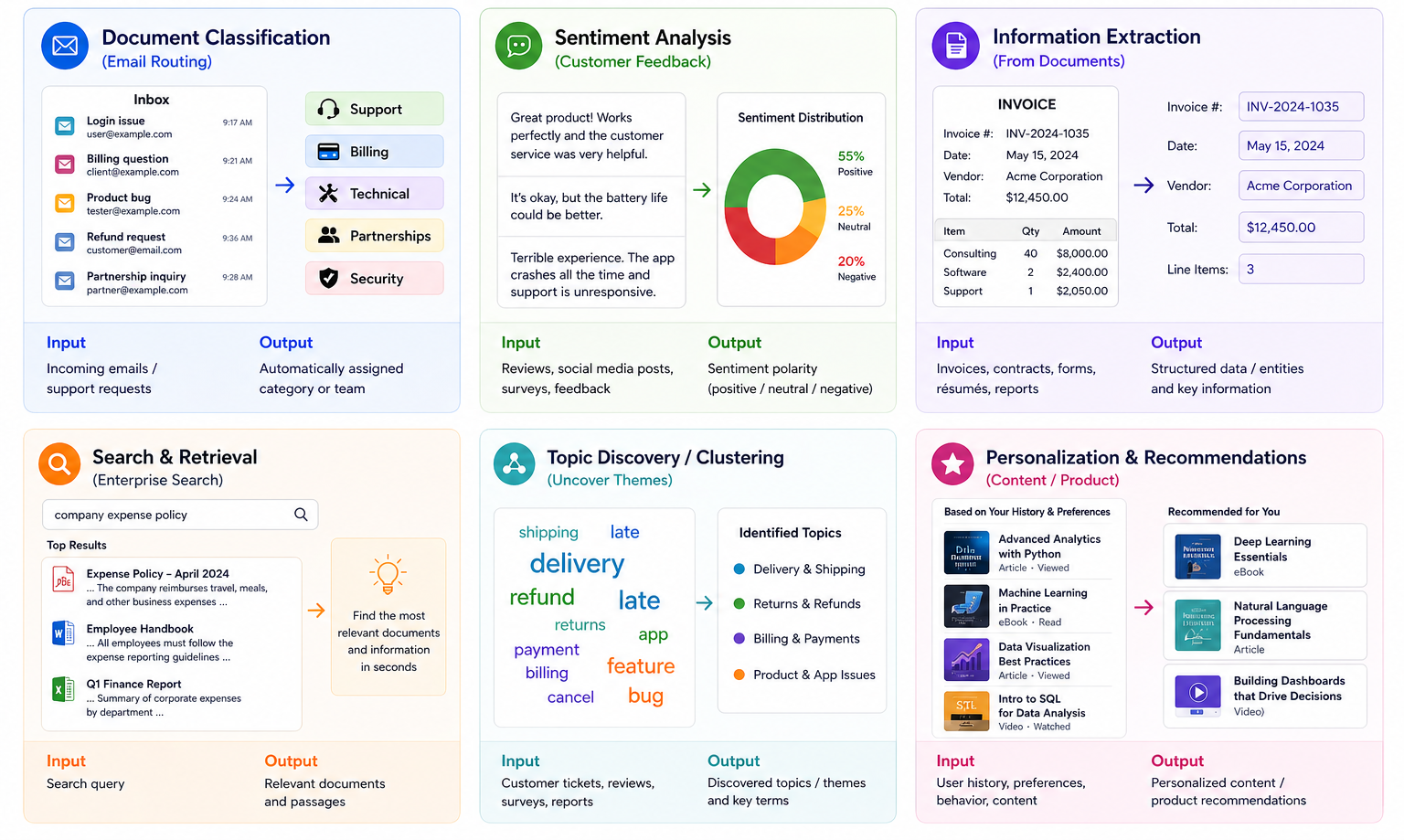
Typical sources of noise
Preprocessing options (choose what fits the analytical approach)
➜
Stopword removal:
➜
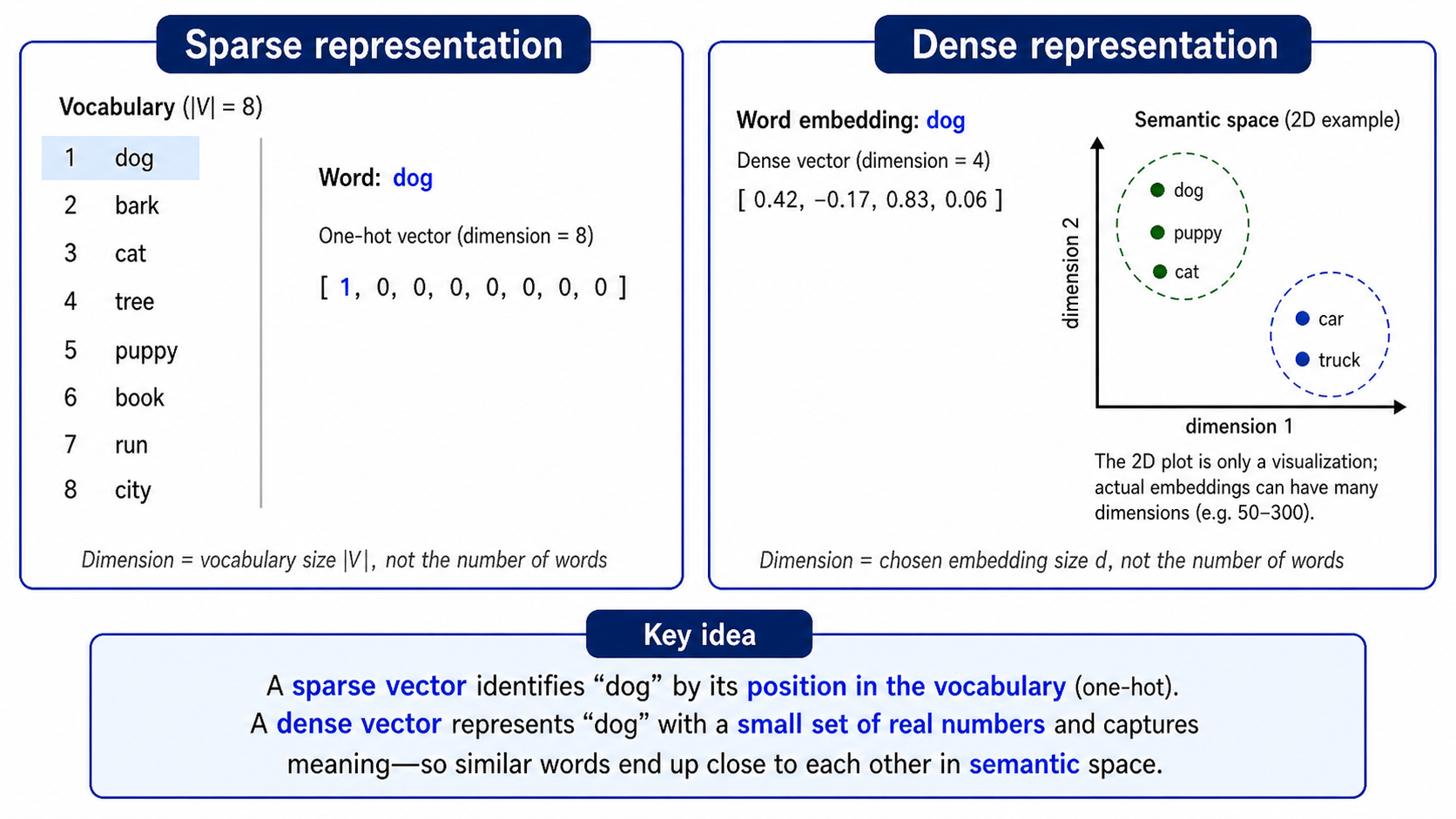
A document is treated as a bag of words or terms.
Key idea: Text is transformed into numerical features that can be used by classical machine learning models.
Ways to create vectors
| Technique | Feature value |
|---|---|
| Binary term occurrence | term appears: yes / no |
| Term occurrence | number of times a term appears |
| Term frequency | occurrences divided by document length |
| TF-IDF | frequency weighted by how distinctive the term is |
➜
TF-IDF (term frequency-inverse document frequency) measures how important a term is to a document relative to a corpus
\[idf_i = log(\frac{N}{df_i})\]
with \(N\): total number of documents
\(df_i\): the number of documents in which \(t_i\) appears.
TF-IDF weight:
\[w_{ij} = tf_{ij} \times idf_i\]
➜
➜
The sentence_transformers library offers pre-trained models for dense vectors:
<class ‘numpy.ndarray’>
(384,)
[-0.042 0.018 0.067 …]
➜
Transformer models combine dense vectors with positional encoding:
![]()
➜
In one-hot encoded documents, or in large corpora, feature selection can help to facilitate computation and avoid overfitting. Two major feature selection approaches in the context of text analytics are:
Pruning methods: removing words that are too infrequent or to frequent, based on absolute or percental thresholds.
Token filtering based on part-of-speech (POS): sometimes, the analyses focus on particular classes of words. For example:
➜
Typical goal: find groups of documents that are similar to each other
Similarity measures for text data
| Representation | Typical similarity measure | Useful for |
|---|---|---|
| Bag-of-Words / TF-IDF | Cosine similarity | comparing word-use patterns |
| Sets of words | Jaccard similarity | overlap between vocabularies |
| Dense embeddings | Cosine similarity / Euclidean distance | semantic similarity |
➜