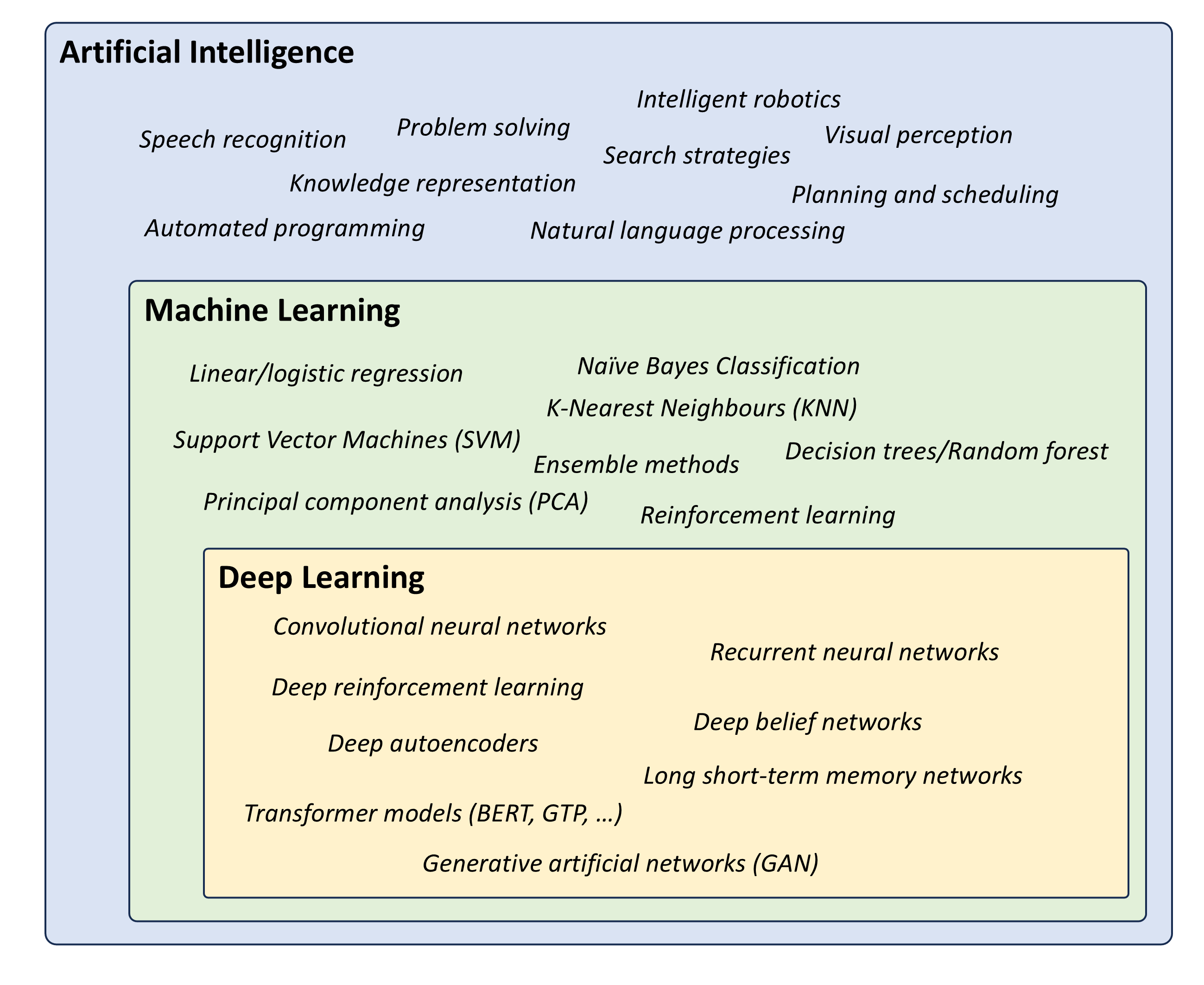
Artificial Intelligence (AI) involves techniques that equip computers to emulate human behavior, enabling them to learn, make decisions, recognize patterns, and solve complex problems in a manner akin to human intelligence.
Machine Learning (ML) is a subset of AI and uses advanced algorithms to detect patterns in large datasets, allowing machines to learn and adapt. ML algorithms use supervised or unsupervised learning methods.
Deep Learning (DL) is a subset of ML that uses neural networks for in-depth data processing and analytical tasks. It leverages multiple layers of artificial neural networks to extract high-level features from raw input data, simulating the way human brains perceive and understand the world.

Note: Our focus will be primarily on supervised machine learning:
\[\underbrace{\text{Dataset}}_\text{Features, Targets} + \underbrace{\text{Learning Algorithm}}_\text{Model Class + Objective + Optimizer } \to \text{Predictive Model}\]
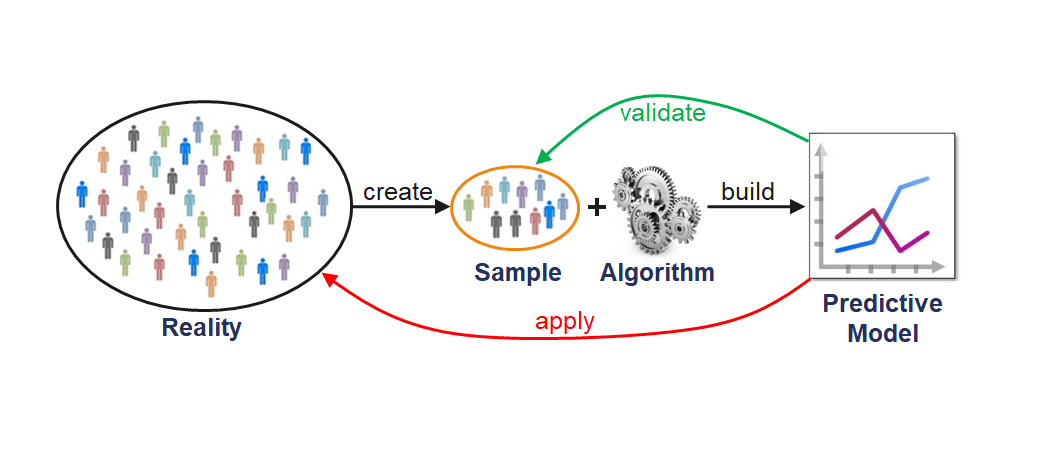
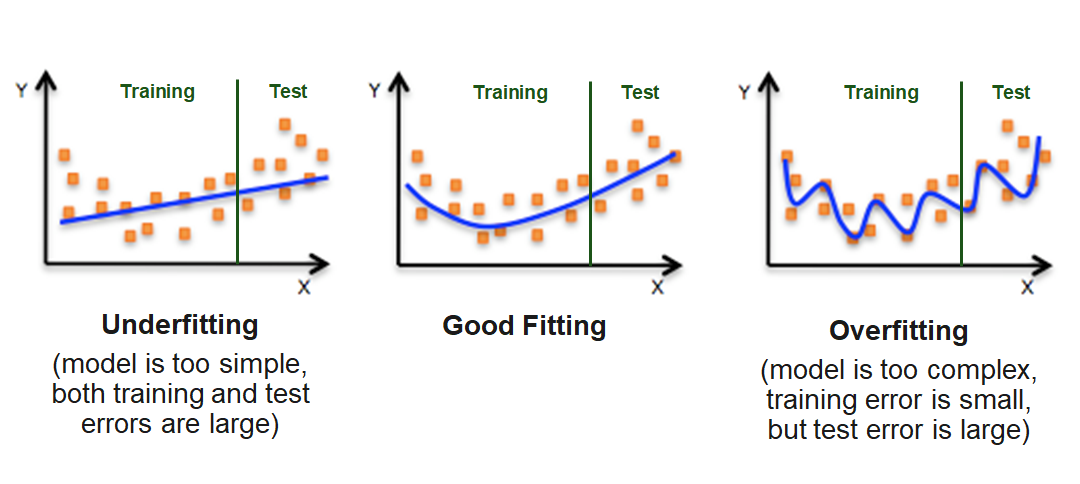
Due to the problem of overfitting, the main goal is to maximize the prediction quality and not to fit the data that is used for the model estimation as well as possible. This is equivalent to minimizing the risk that the model will have weak predictive ability.
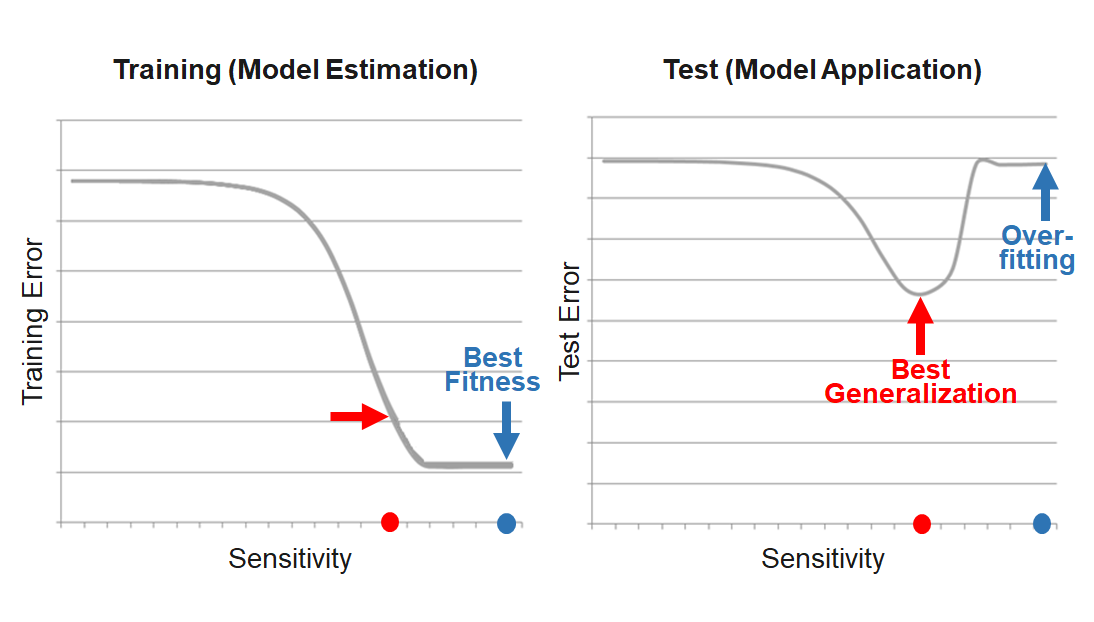
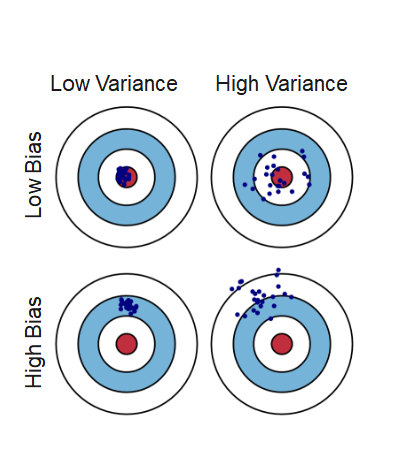
The prediction error is influenced by three components:
Error = Bias + Variance + Noise
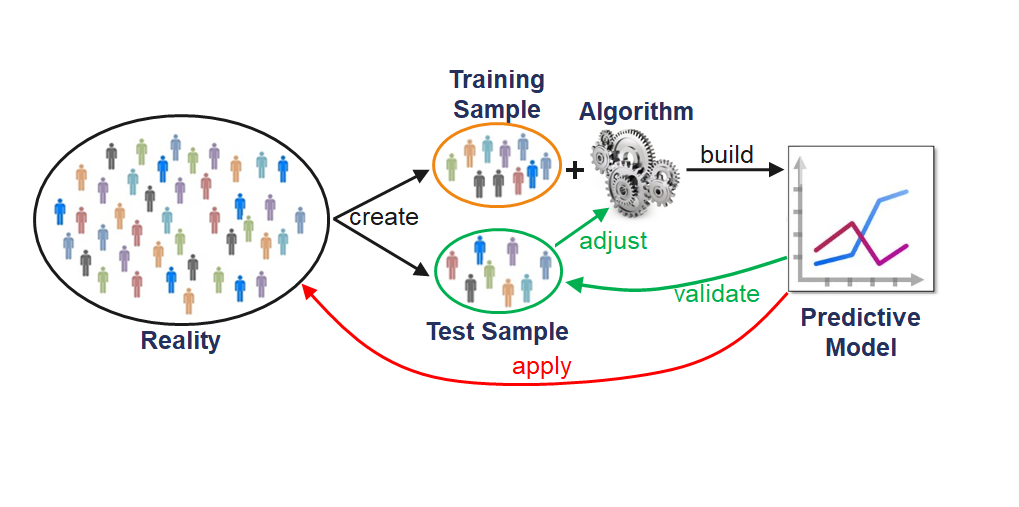
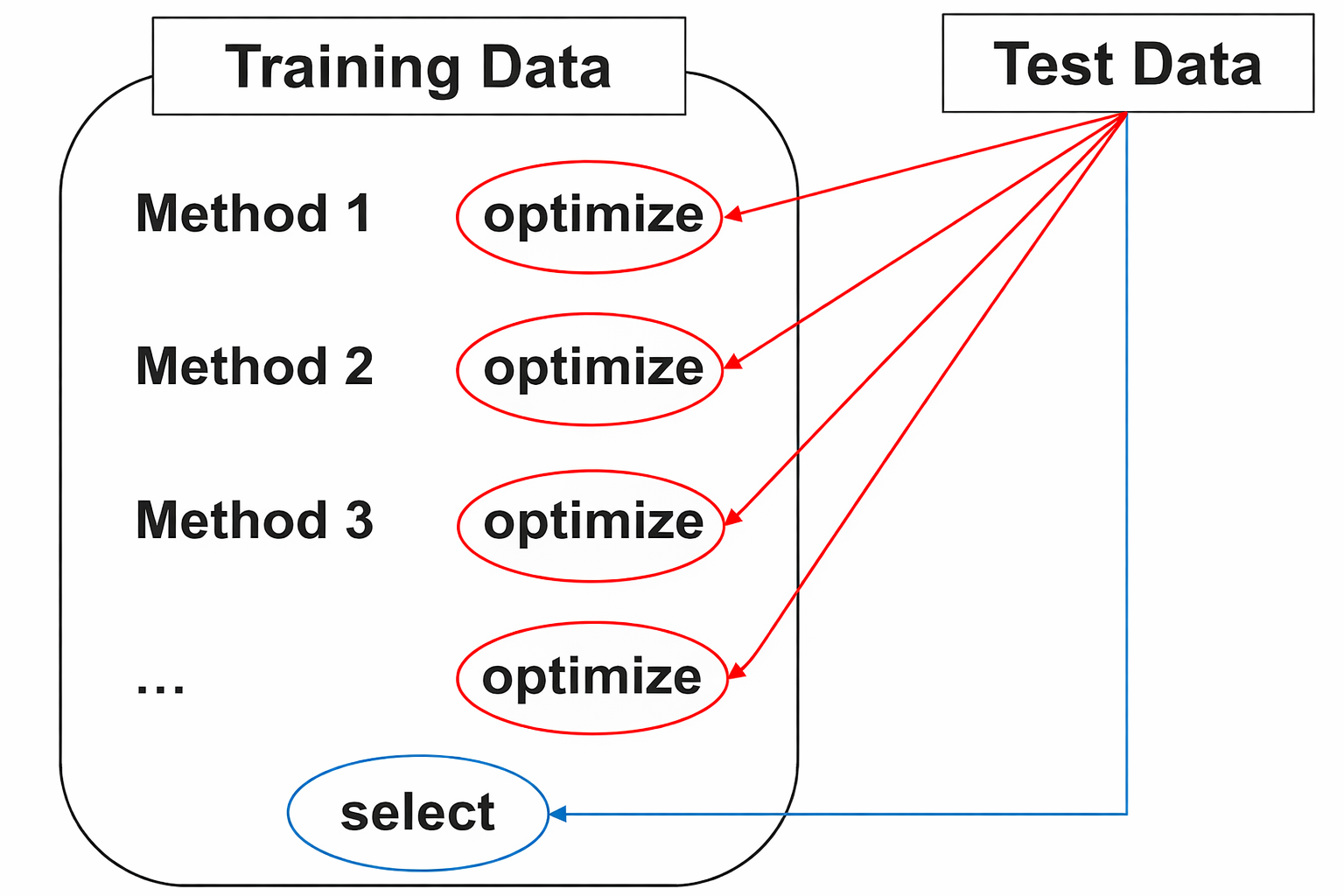
Problematic use of test data for two purposes:
1. Optimize the model training
2. Select the best model via testing the model quality
This contradicts the idea of independent testing and results in:
Rule: NEVER use any information from the test data for model training!
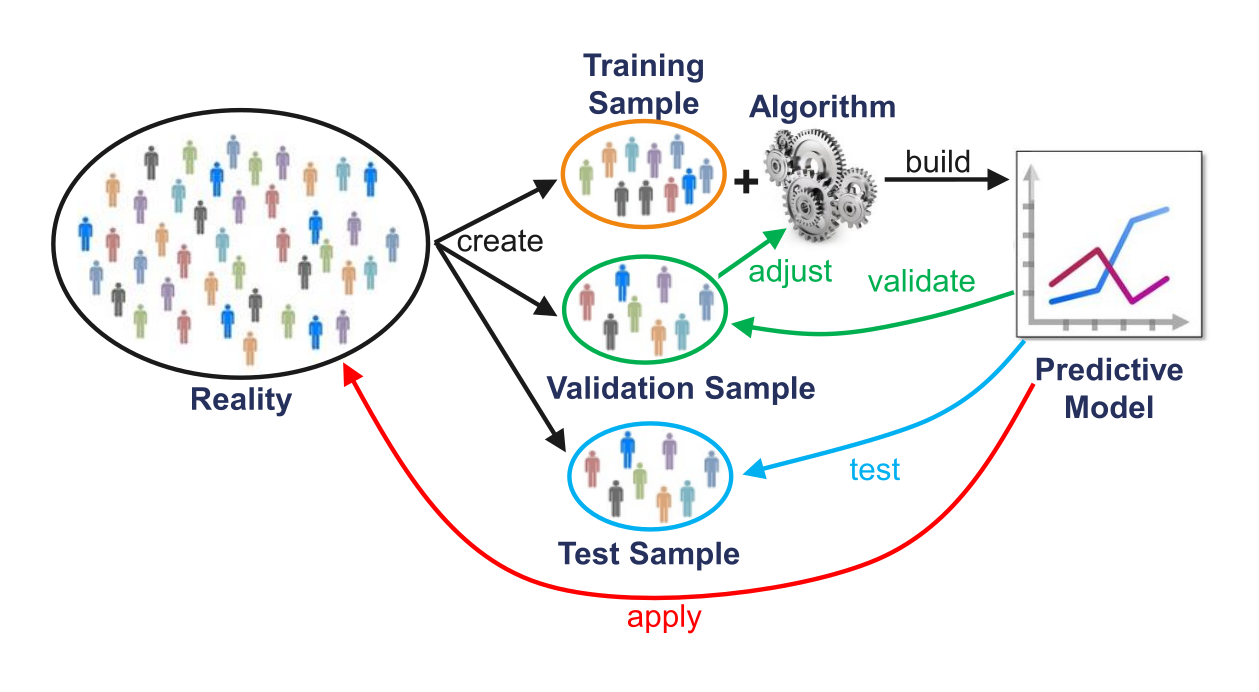
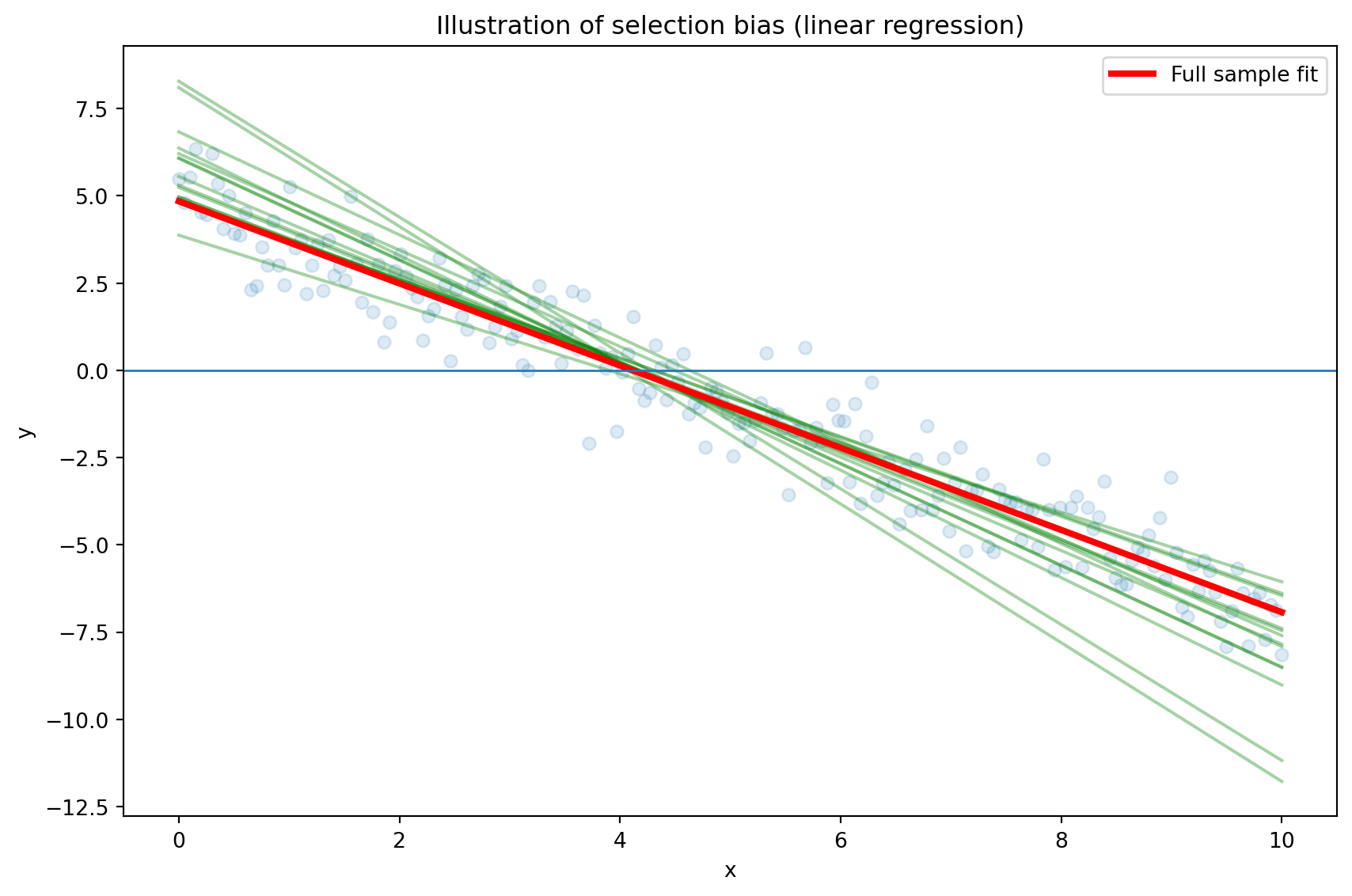
Training and test error can be highly variable, depending on precisely which observations are included in the training set and which observations are included in the validation set (selection bias).
Example of different OLS models as a result of different samples:
To avoid such problems, one can use so-called resampling methods.
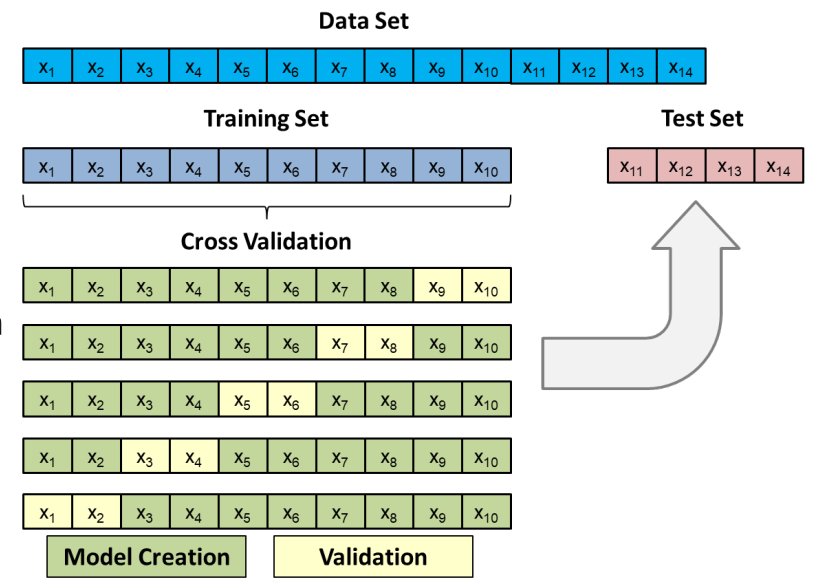
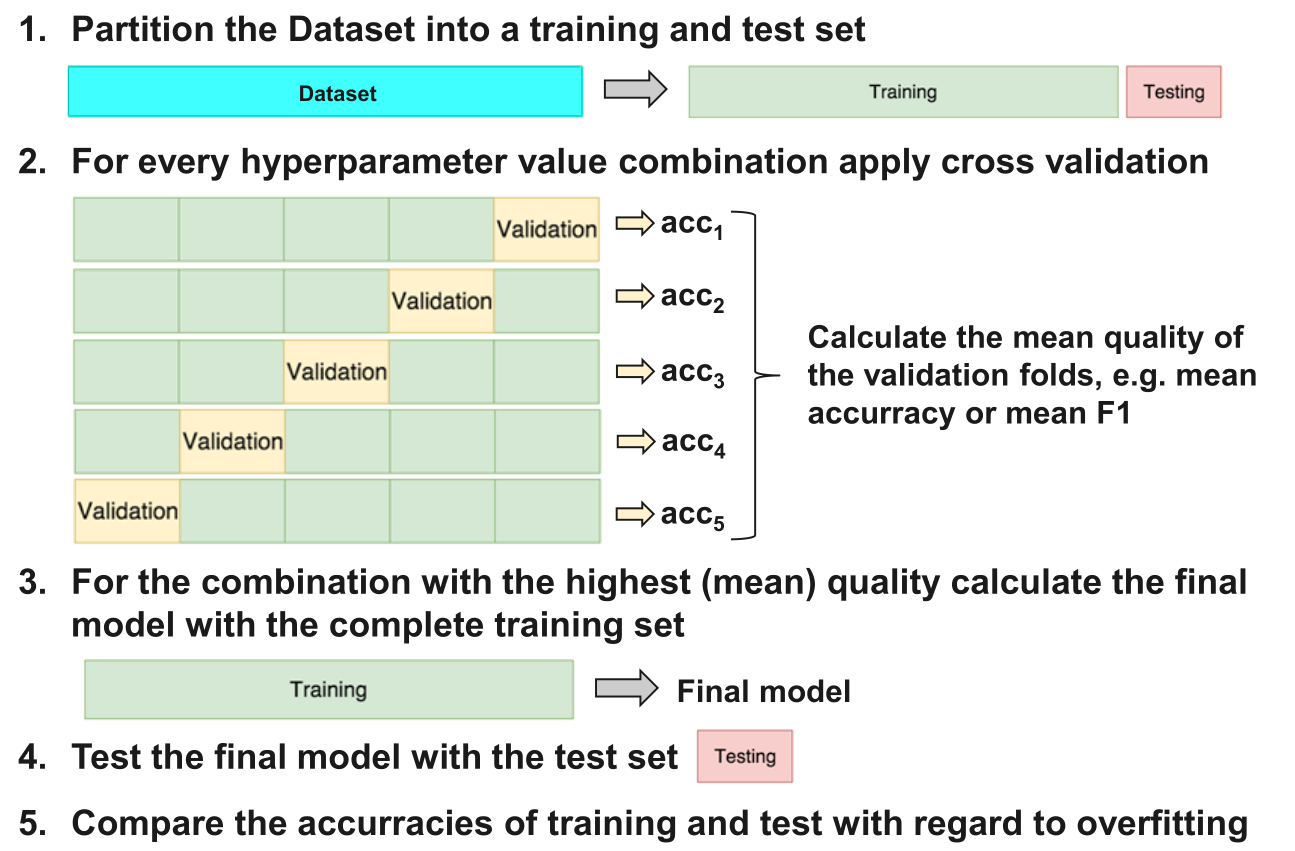
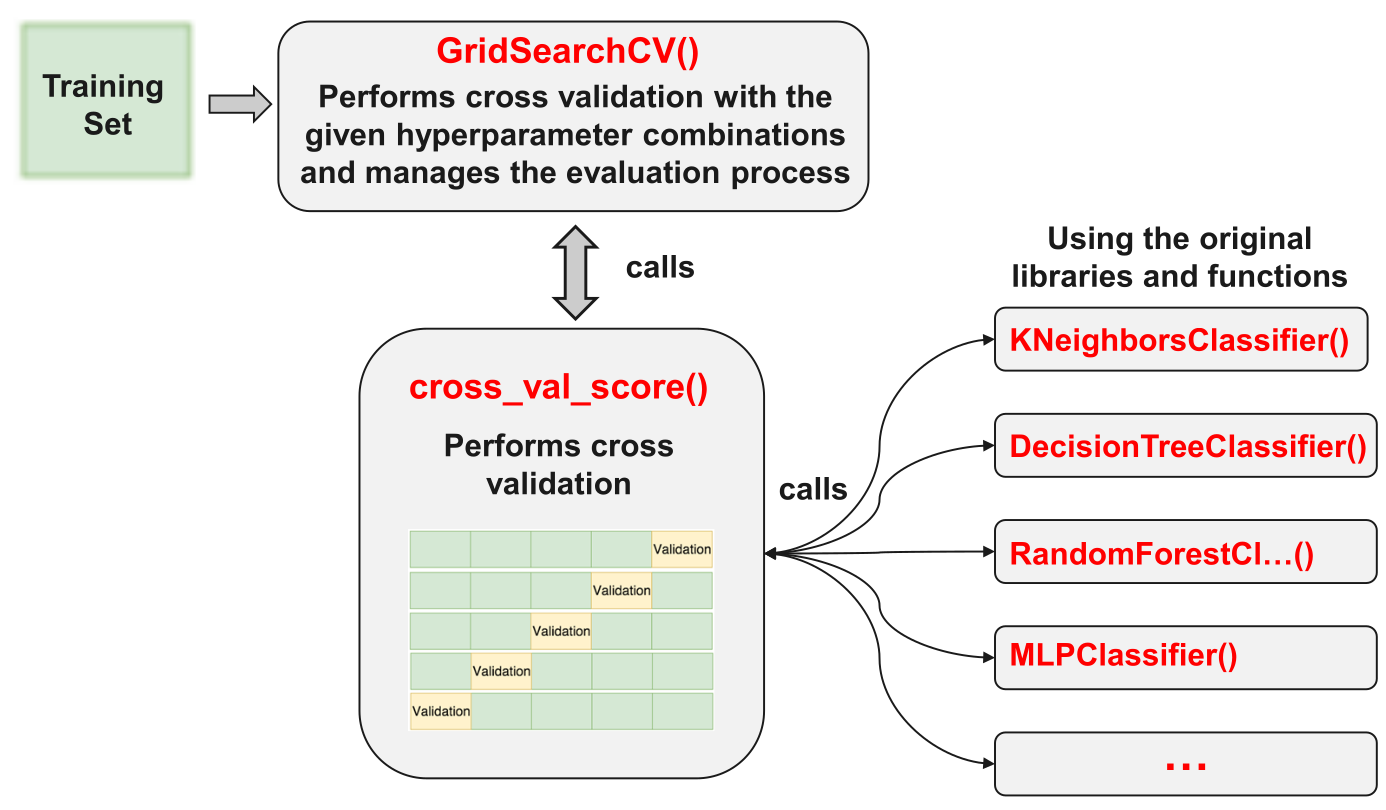
Cross validation can be used for model selection and adjustment. In these cases, cross validation is applied to the training dataset. For every iteration, k-1 folds are used for model fitting and the remaining fold for testing the model (Validation). Every time, the quality measure (e.g. accuracy) for the validation fold is captured. At the end of this step, the average and the standard deviation of the measures are calculated. The best model is the one with the best ratio in high average and low standard deviation.
Once the model type and its optimal parameters have been selected, a final model is trained using these hyper-parameters on the full training set, and the generalization quality is measured on the test set.
Feature engineering is the process of using domain knowledge of the data to create features that make machine learning algorithms work. When done correctly, feature engineering increases the predictive power of machine learning algorithms by creating features from raw data that help facilitate the machine learning process.
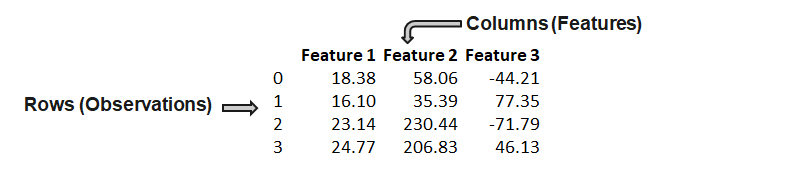
A feature (variable, attribute) is depicted by a column in a dataset. Considering a generic two-dimensional dataset, each observation is depicted by a row and each feature by a column, which will have a specific value for an observation:
Features can be of two major types.
Many machine learning algorithms cannot work with categorical data directly. To convert categorical data to numbers, there exist two variants:
Label encoding refers to transforming the word labels into numerical form so that the algorithms can understand how to operate on them. Every categorical value is assigned to one numerical value, e.g. young → 1, middle_age → 2, old → 3. This only works in specific situations where you have somewhat continuous-like data, e.g. if the categorical feature is ordinal.
One hot encoding is a representation of a categorical variable as binary vectors. Every categorical value is assigned to an artificial binary variable. If the corresponding categorical value occurs in a data row the value of its binary replacement is equal to 1 else 0, e.g.
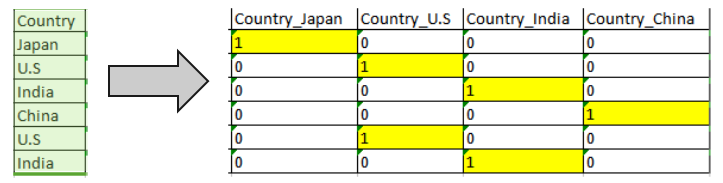
It is usual when creating dummy variables to have one less variable than the number of categories present to avoid perfect collinearity (dummy variable trap).
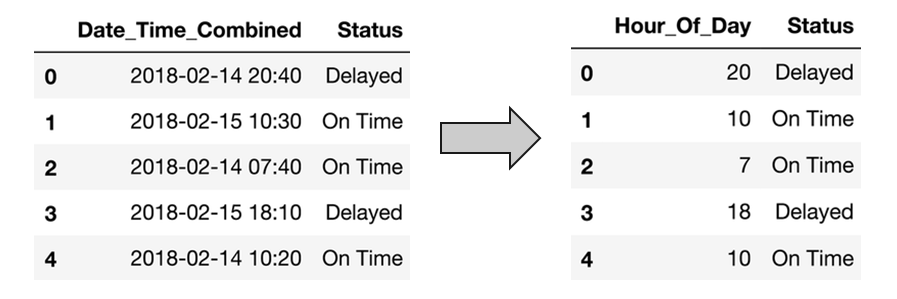
Datasets often contain date/time features. These features are rarely useful in their original form because they only contain ongoing values. However, they can be useful for extracting cyclical factors, such as weekly or seasonal effects. Suppose, we are given a data “flight date time vs status”. Then, given the date-time data, we have to predict the status of the flight.
But the status of the flight may depend on the hour of the day, not on the date-time. To analyze this, we will create the new feature “Hour_Of_Day”. Using the “Hour_Of_Day” feature, the machine will learn better as this feature is directly related to the status of the flight.