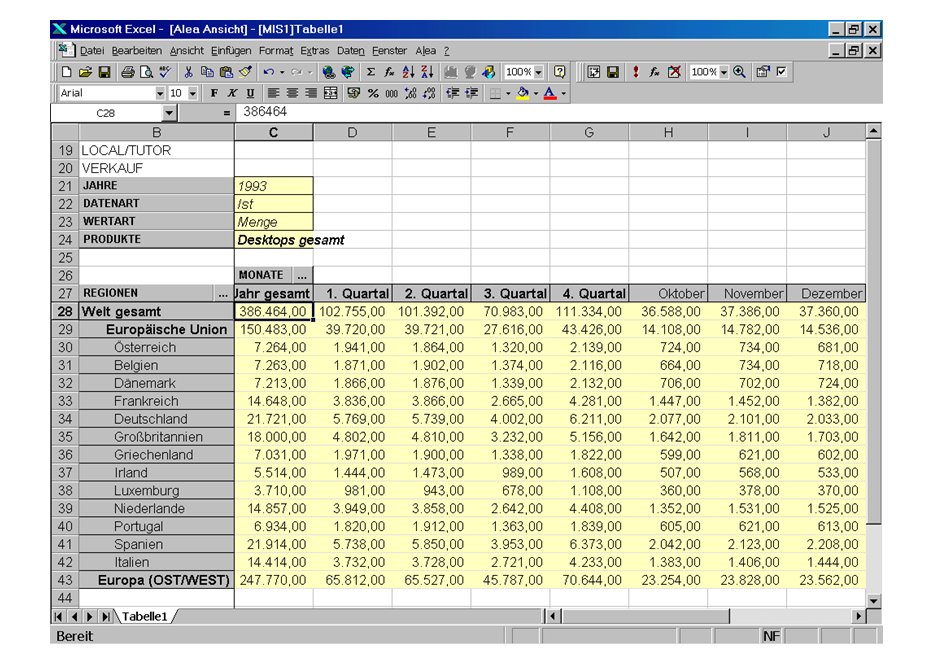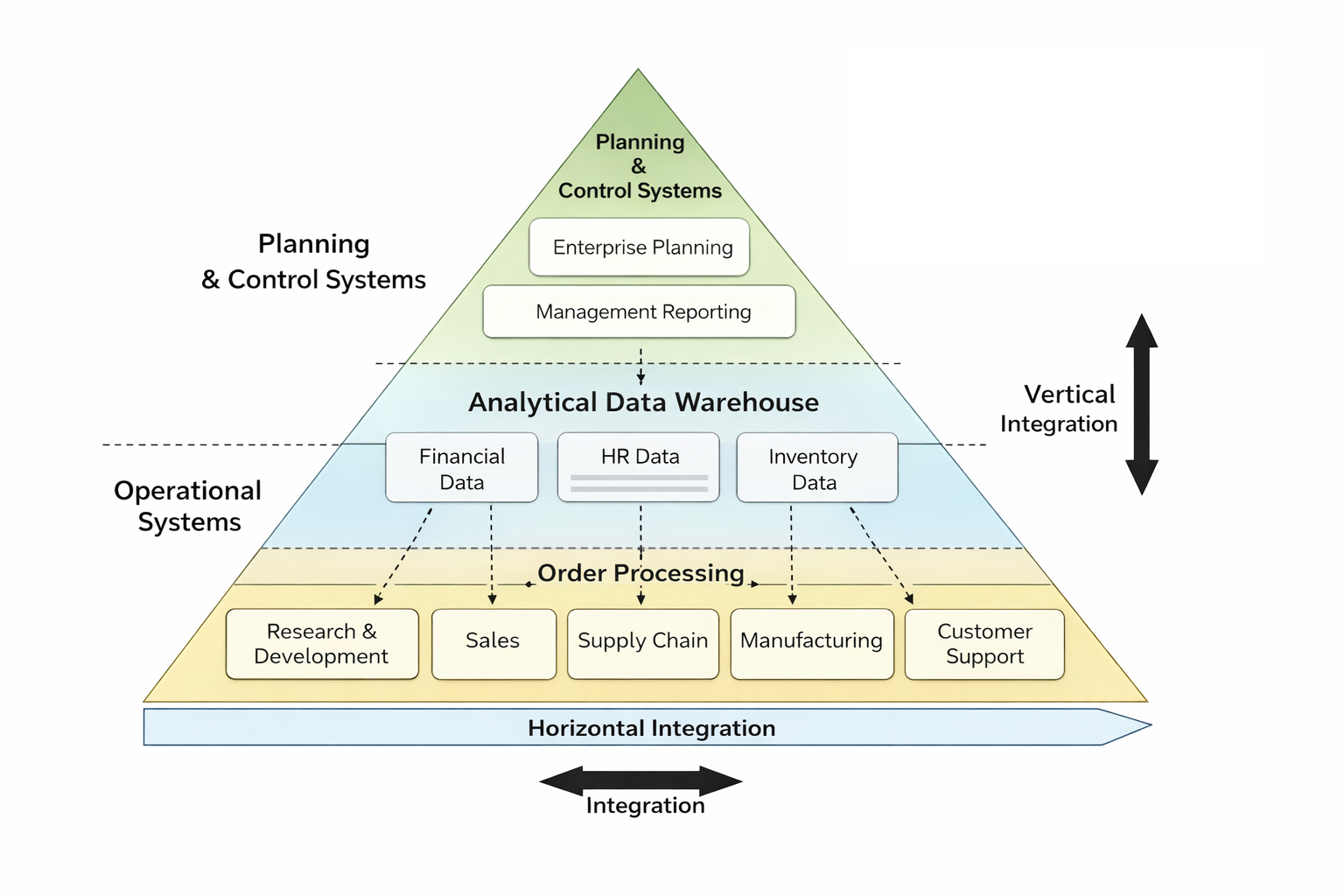
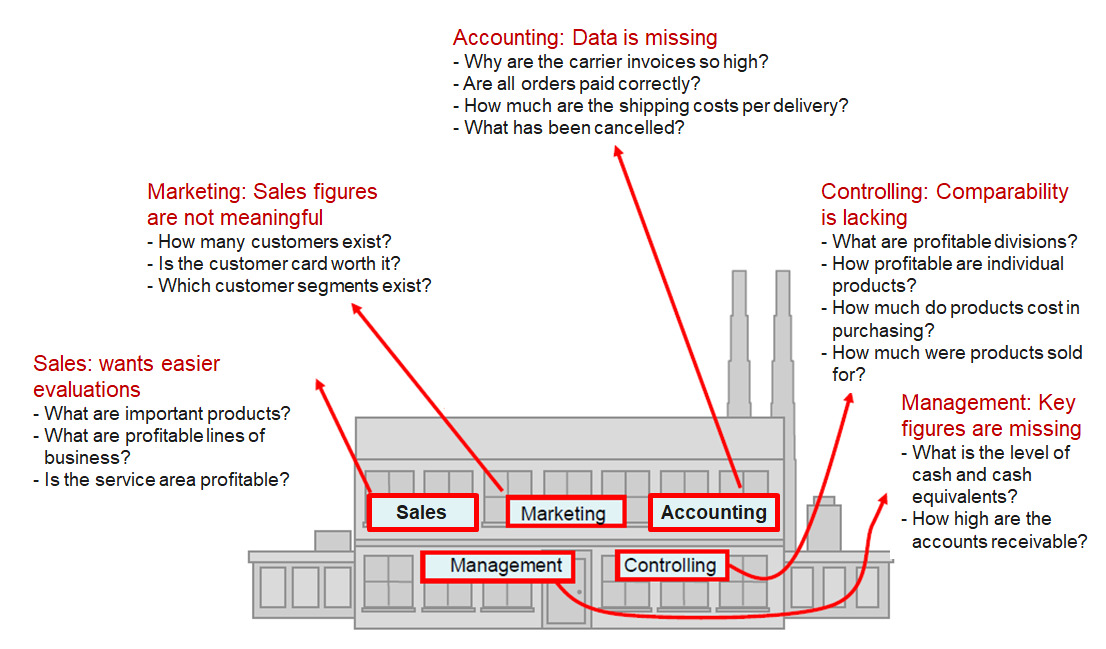
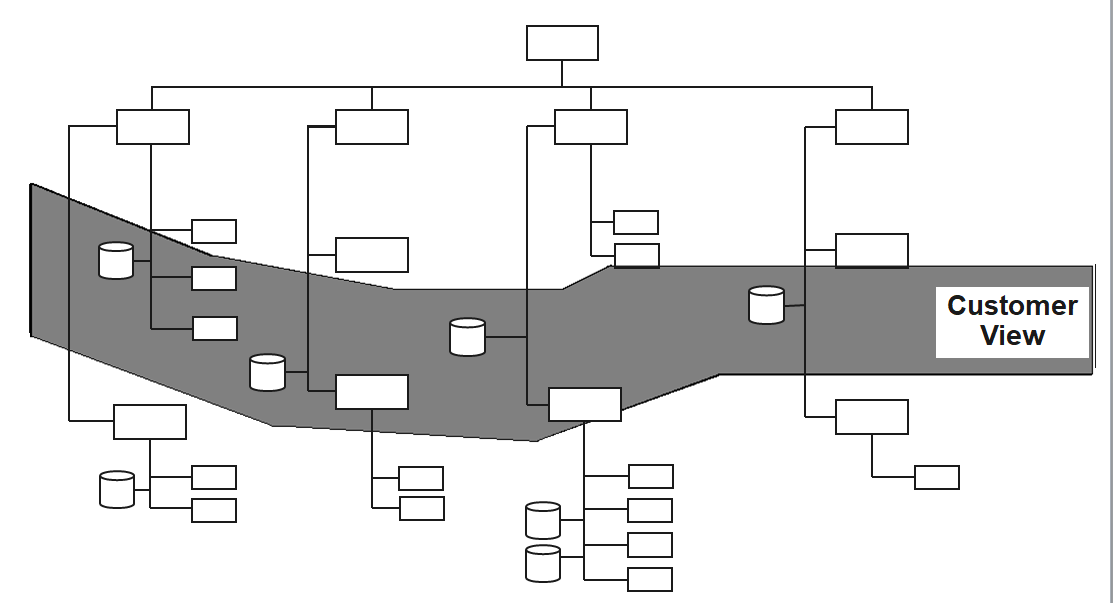
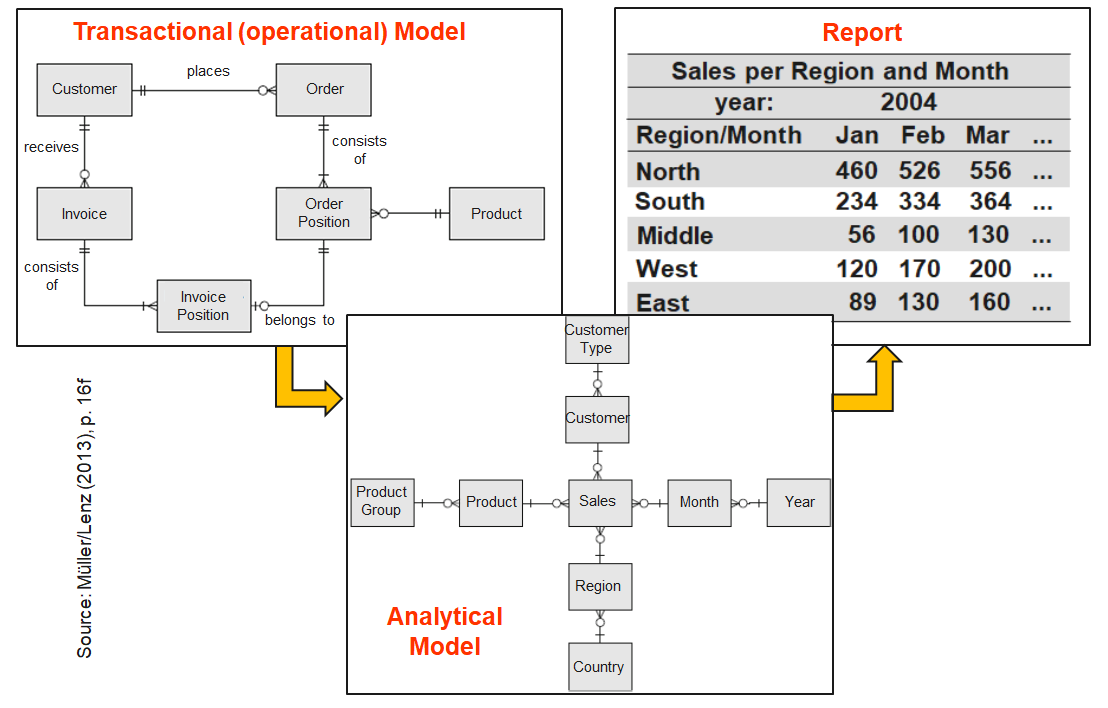
Organizations structure operational data by departments and processes, but analytical questions require cross-departmental views.
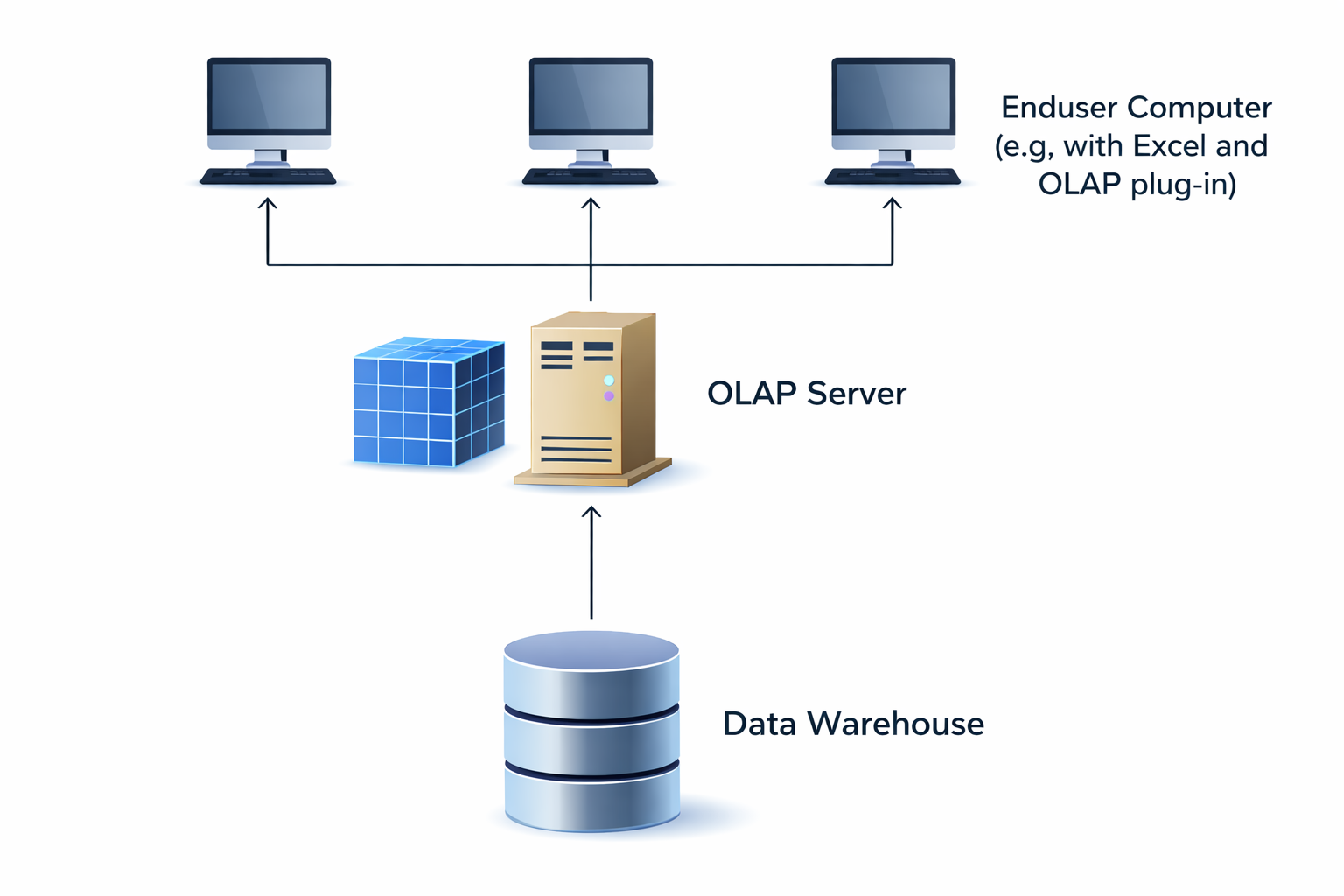
The hardware load differs in operational application systems and data warehouse systems over time
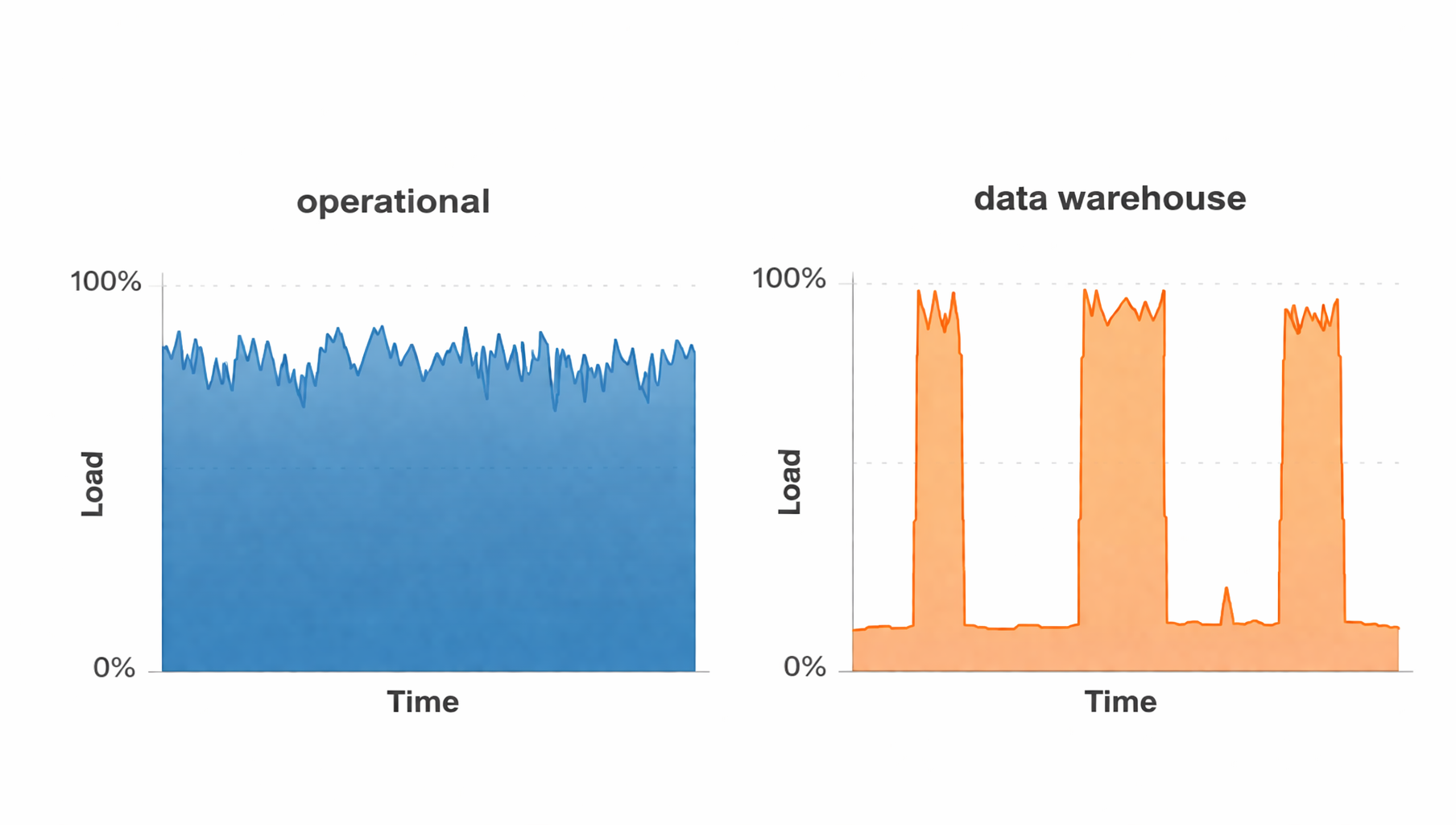
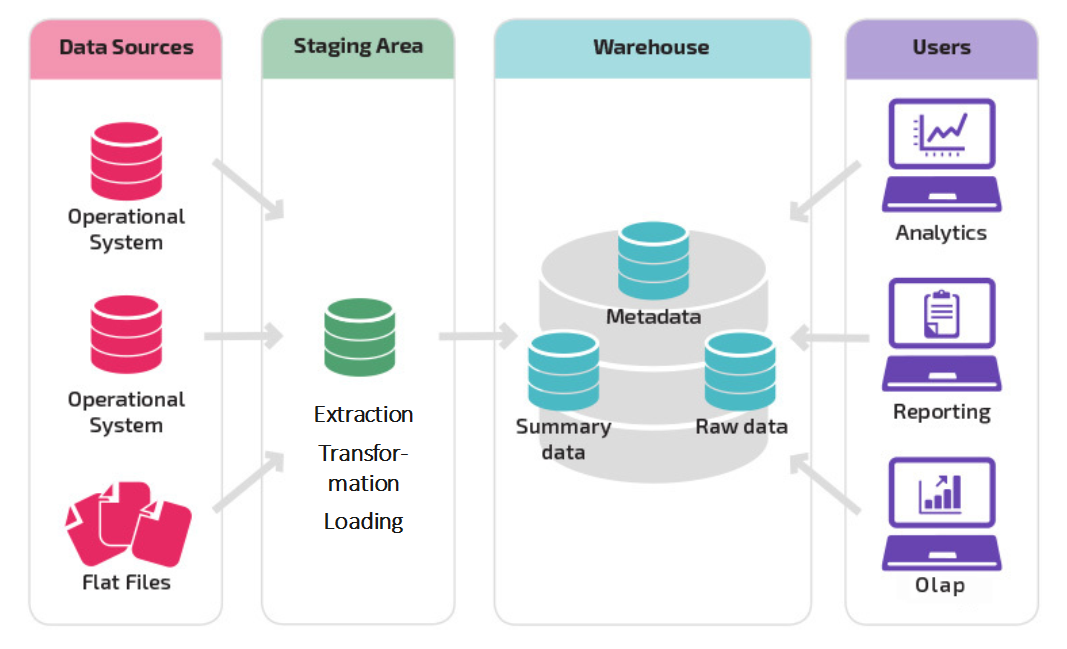
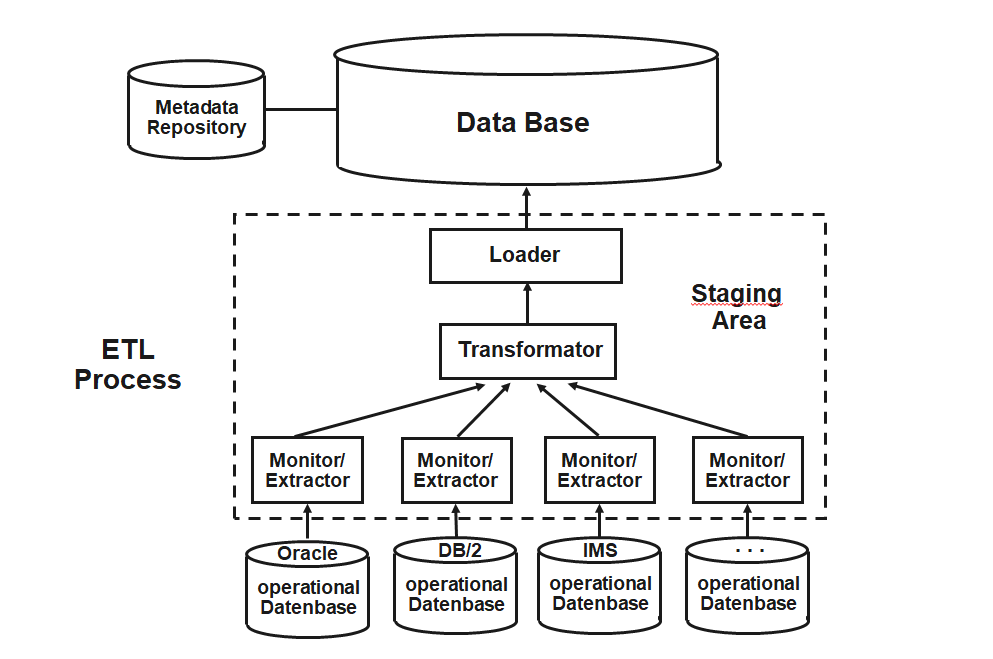
=> A data warehouse relieves the operational systems
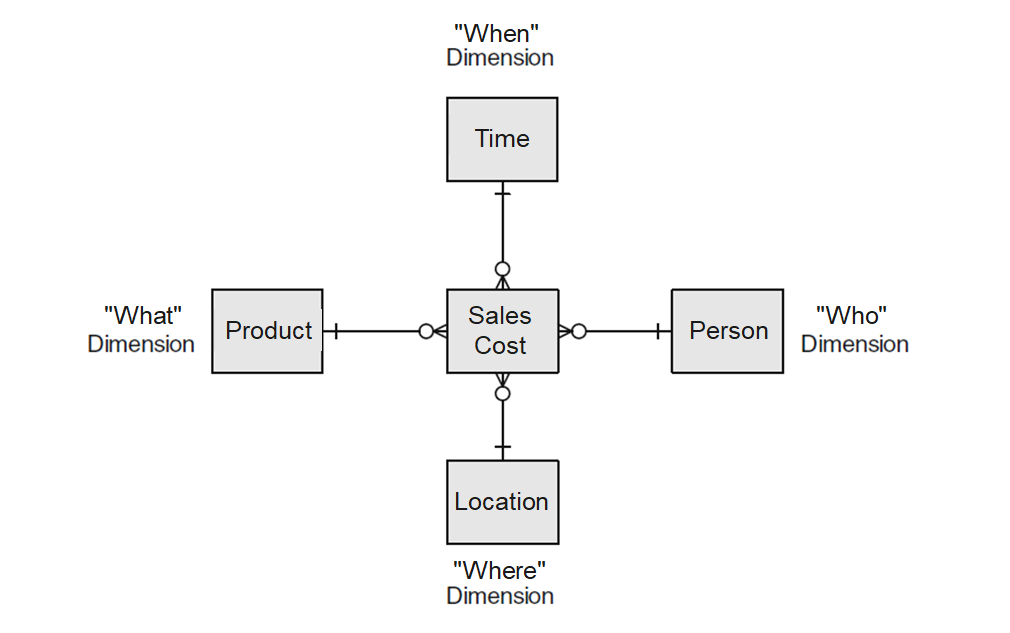
The Star schema has a central fact table and exactly one dimension table for each dimension.
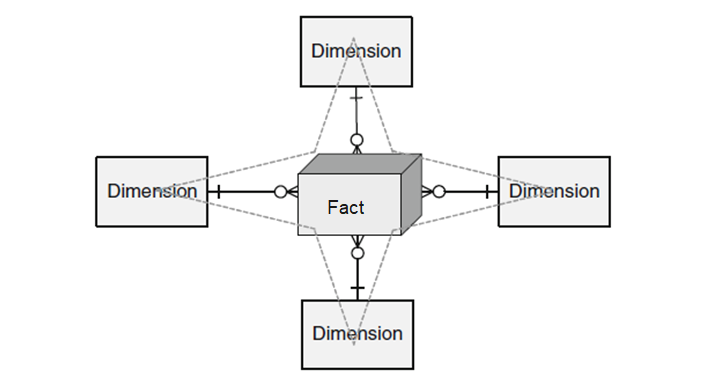
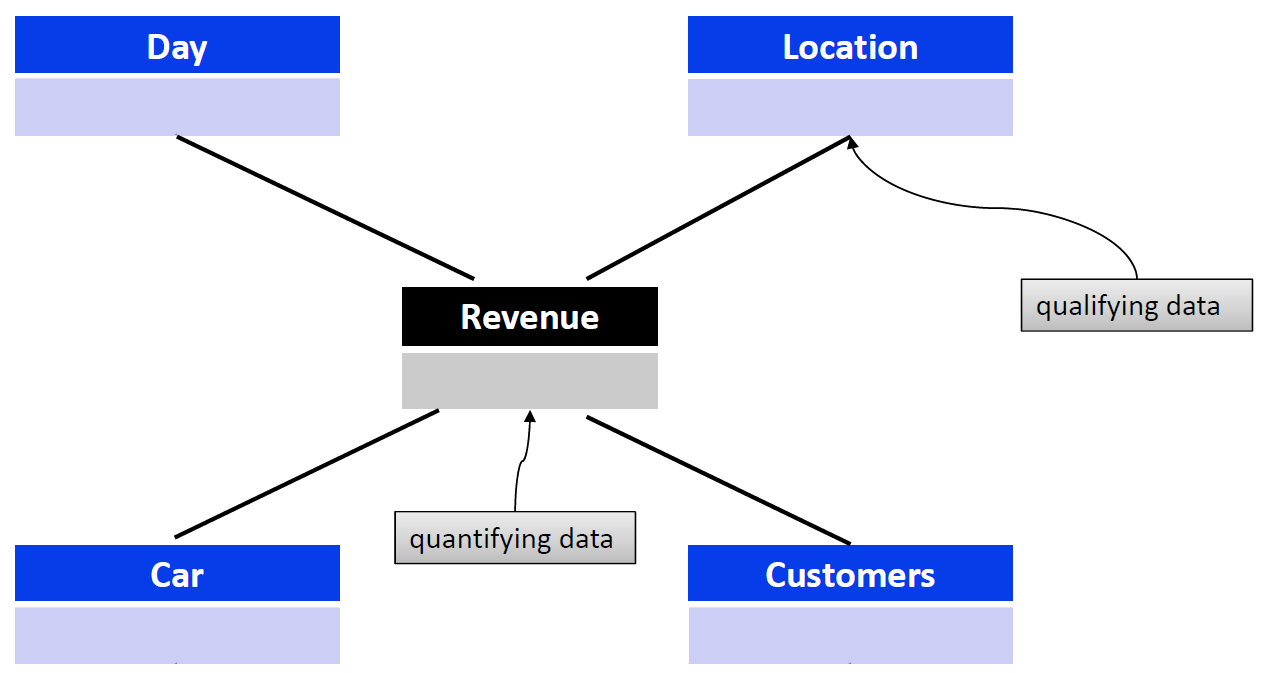
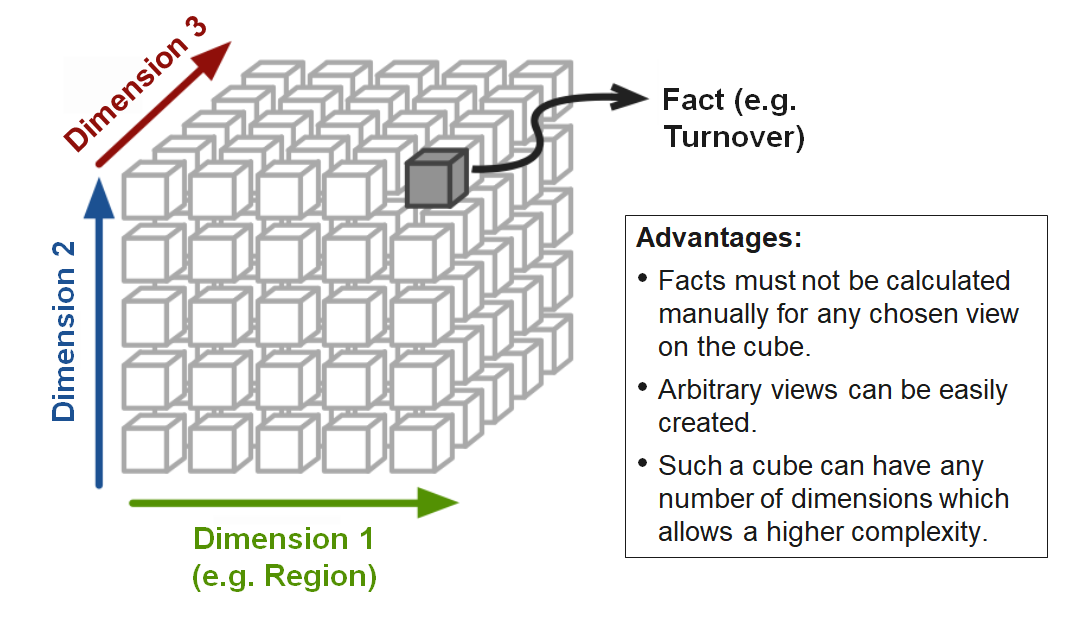
The cardinality between the fact table and a dimension table is n∶1, i.e. a fact (e.g. sales: 67,000 euros) is described by one dimension expression for each dimension (e.g. time: 1st quarter, region: Hesse, product group: books). A dimension characteristic (e.g. product group: books) is associated with 0, 1 or n facts.
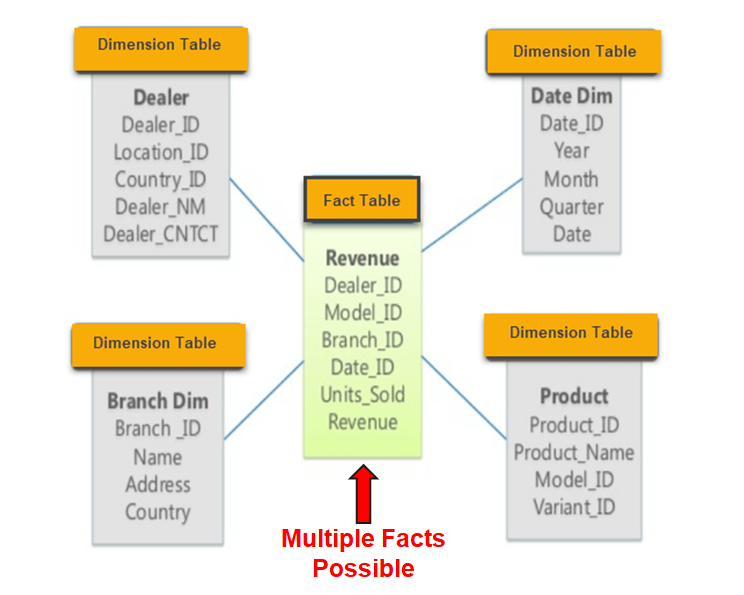
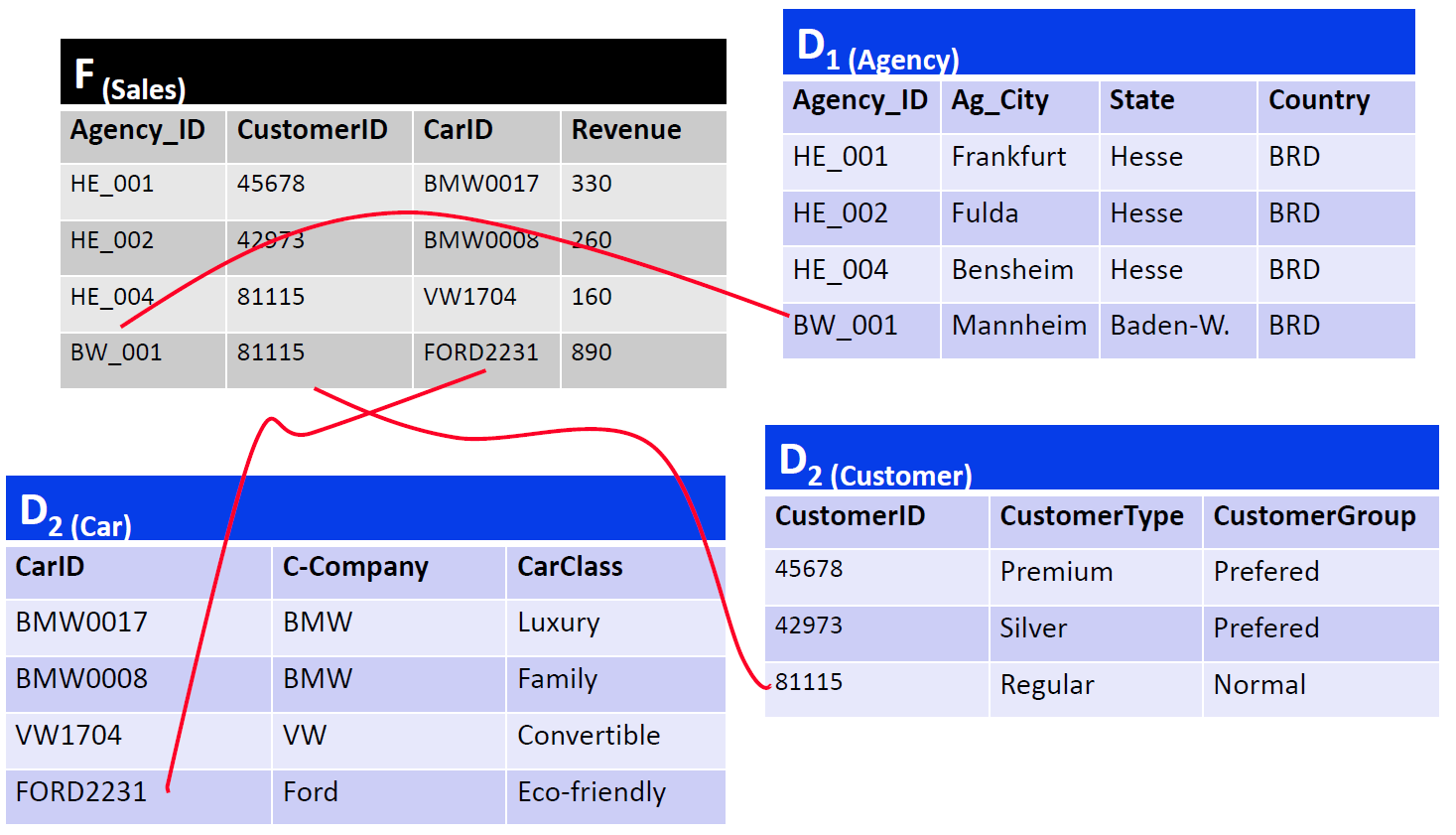
In the Snowflake schema, the redundancies in the Star schema are resolved in the dimension tables and the hierarchy levels are each modeled with their own tables:
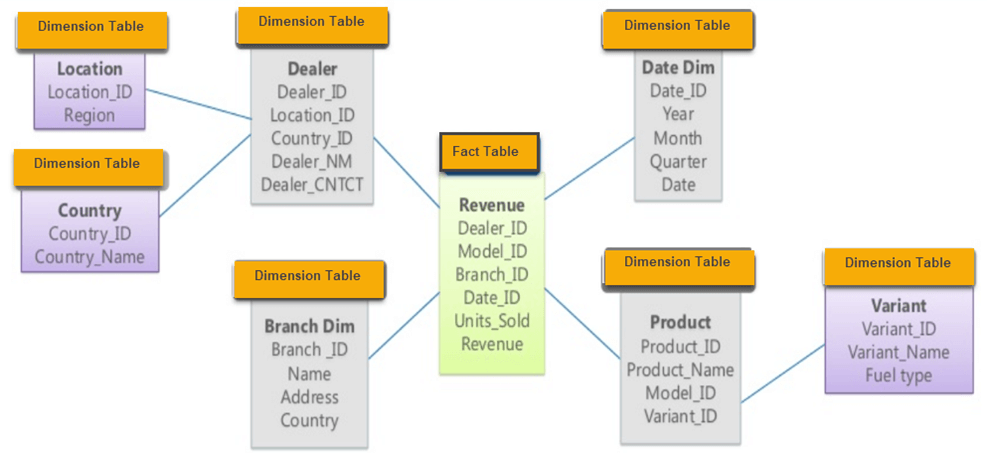
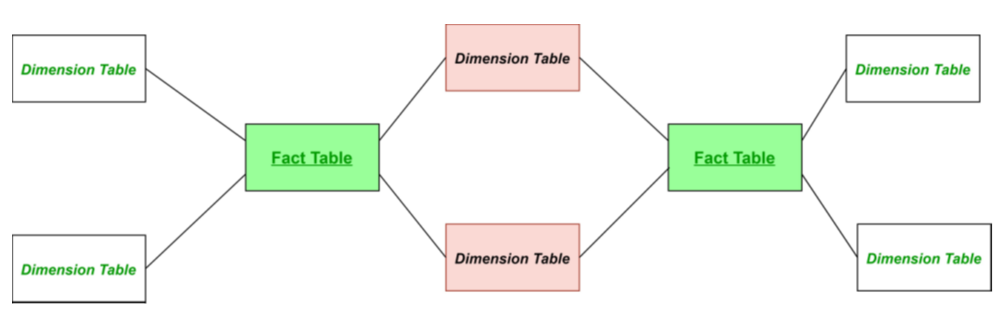
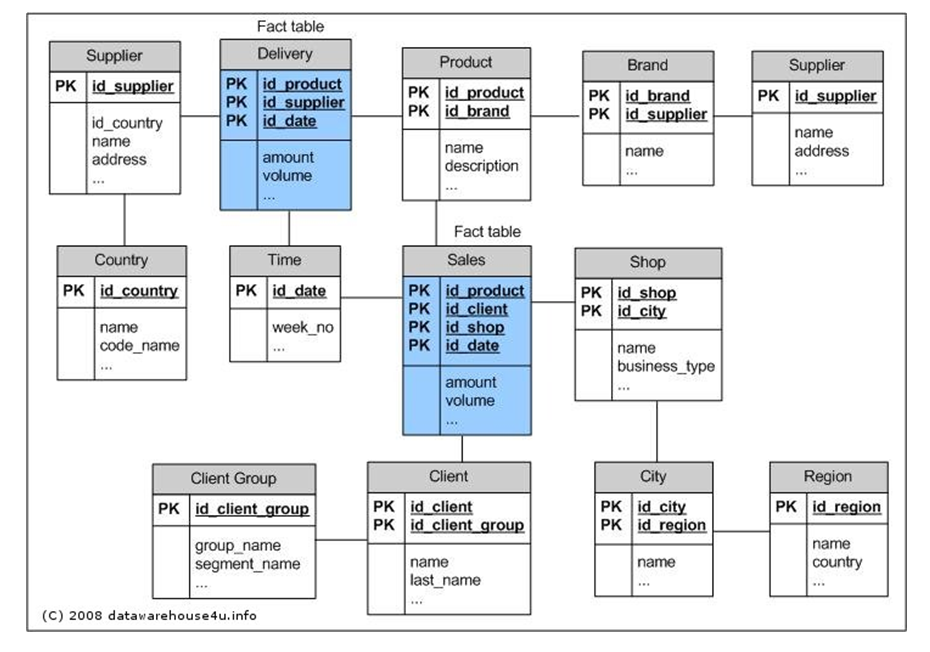
The Galaxy schema contains more than one fact table. The fact tables share some but not all dimensions. The Galaxy schema thus represents more than one data cube (multi-cubes).
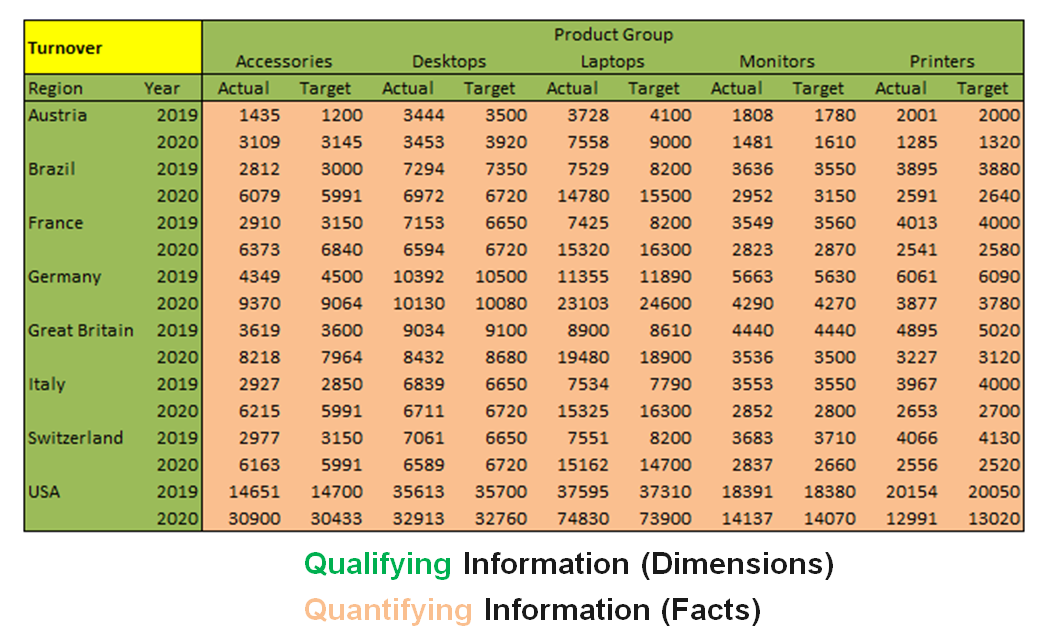
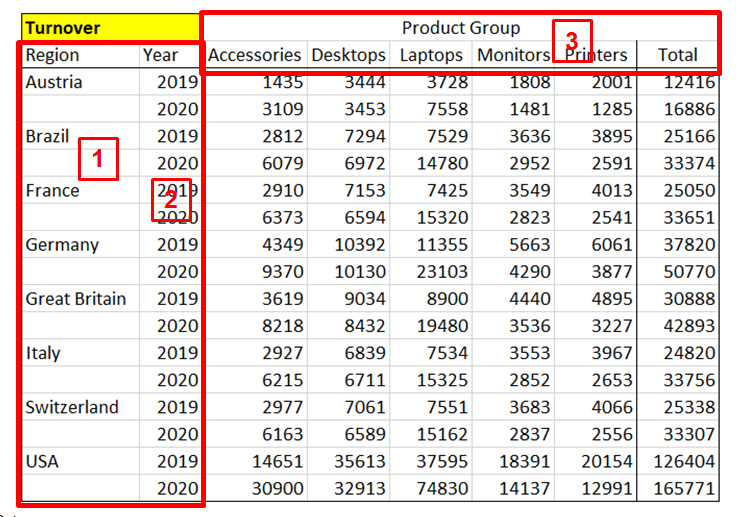
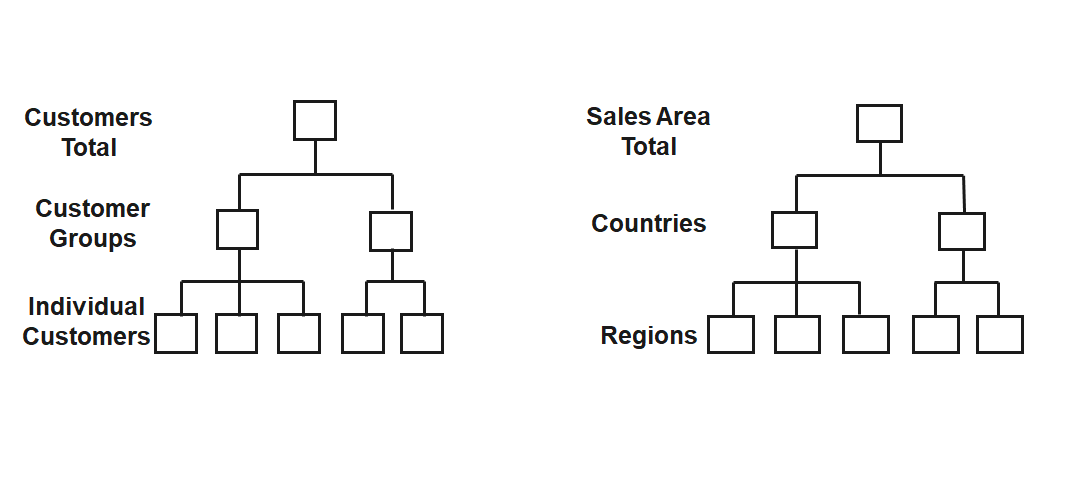
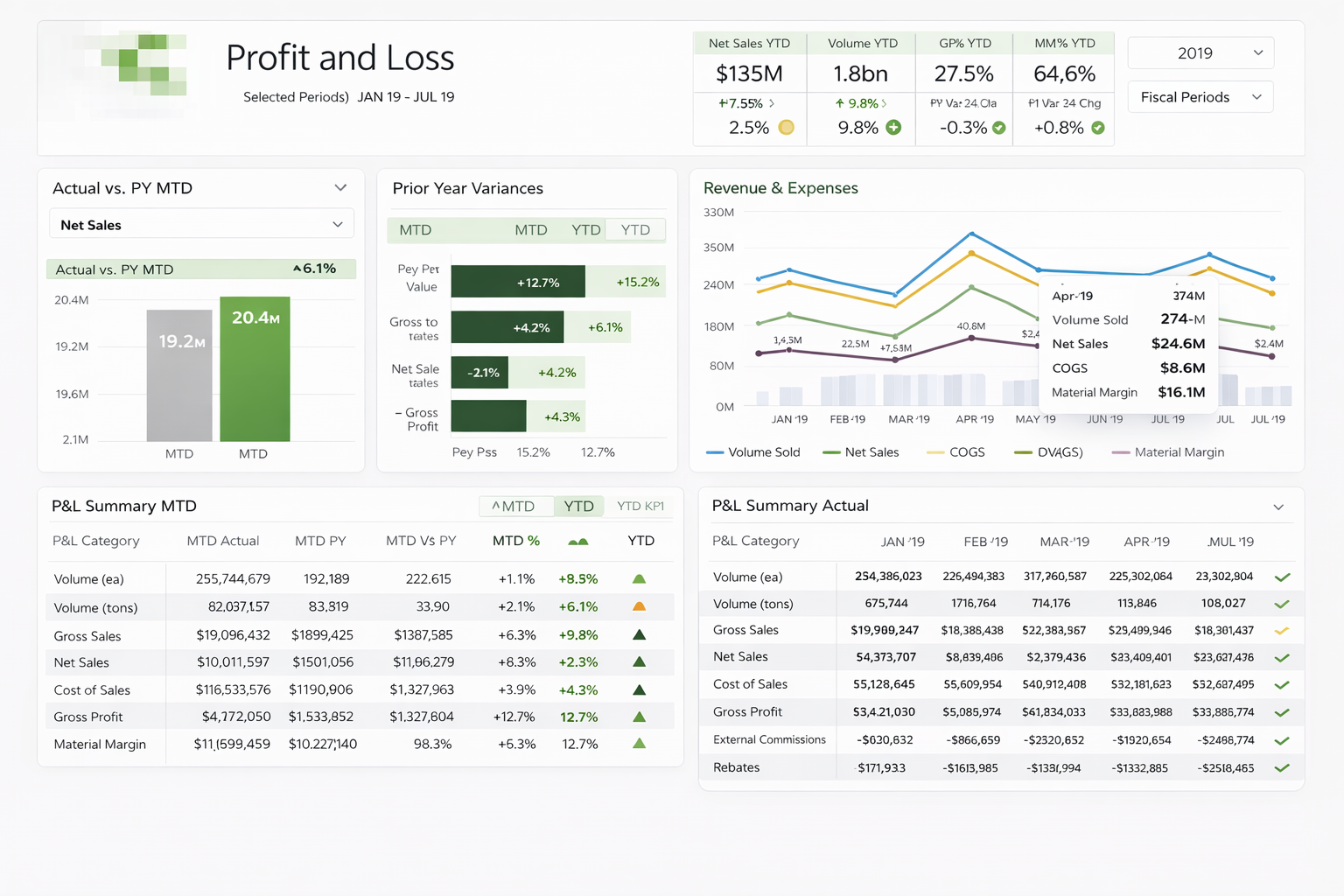
The result of a nest operation physically represents a two-dimensional matrix. It is extended by displaying different hierarchy levels of one or more dimensions on one axis (column or row) in nested form. In the following example, three dimensions are displayed: