Notes: Session 7: Machine learning 2
2026-04-20: 95 min (skipped regression trees and support vector regression)
| Time (min) | Duration | Topic | Additional materials |
|---|---|---|---|
| 0–90 | 90 | TODO |
TODO:
- Better prepare the explanation of decision trees (entropy, information gain) (see https://www.cs.cmu.edu/~aarti/Class/10315_Fall20/recs/DecisionTreesBoostingExampleProblem.pdf)
- Check regression trees carefully
- Prepare explanation and visualization of SVMs (on the slides)
Decision trees
ID3 algorithm (entropy)
1) Intuition and Definition
Entropy is a measure of how mixed or impure the labels in a dataset are.
- If all observations belong to the same class → low entropy (0) → perfectly pure
- If observations are evenly distributed across classes → high entropy → maximum uncertainty
Formally, for a dataset with (K) classes and class probabilities (p_1, , p_K):
\[H = - \sum_{i=1}^{K} p_i \log_2 p_i\]
This captures the expected amount of information (uncertainty) in the labels.
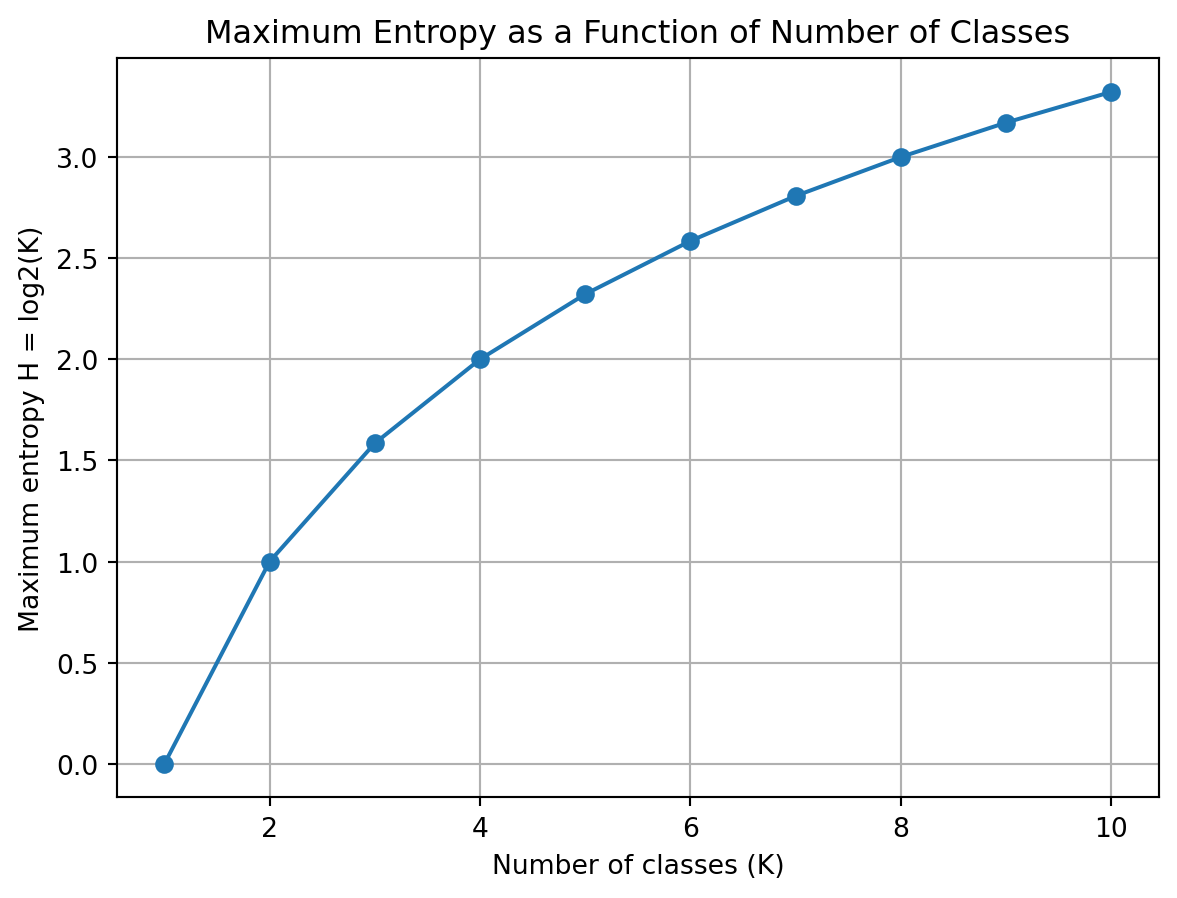
2) Key Teaching Insight: What Is the Maximum Entropy?
A common misconception is that entropy is always between 0 and 1 — this is only true for binary classification. In general, entropy depends on the number of classes (K).
Entropy is maximized when all classes are equally likely:
\[p_1 = p_2 = \dots = p_K = \frac{1}{K}\]
Substituting into the entropy formula:
\[H = - \sum_{i=1}^{K} \frac{1}{K} \log_2 \left(\frac{1}{K}\right)\]
Now simplify:
\[H = - K \cdot \frac{1}{K} \cdot \log_2 \left(\frac{1}{K}\right)\]
\[H = - \log_2 \left(\frac{1}{K}\right)\]
Using the log rule:
\[\log_2 \left(\frac{1}{K}\right) = -\log_2 K\]
So:
\[H = \log_2 K\]
Important takeaway:
Maximum entropy is not fixed
It grows with the number of classes
For example:
- \(K = 2 \Rightarrow H = 1\)
- \(K = 4 \Rightarrow H = 2\)
- \(K = 8 \Rightarrow H = 3\)
4) Python Illustration (Entropy vs. Number of Classes)
Entropy is best understood as:
“A measure of how uncertain we are about the class label.”
- Low entropy → clear, predictable classification
- High entropy → mixed, uncertain data
- Maximum entropy = \(\log_2(K)\) → depends on how many classes exist
This is exactly why decision trees aim to reduce entropy through splits (information gain).
SVM
Maximal margin classifier
Small M&A teams are successful, large teams unsuccessful.
A simple baseline would place the threshold halfway between the class means. The maximal margin classifier instead places the threshold halfway between the closest opposing cases and maximizes the distance to both classes.
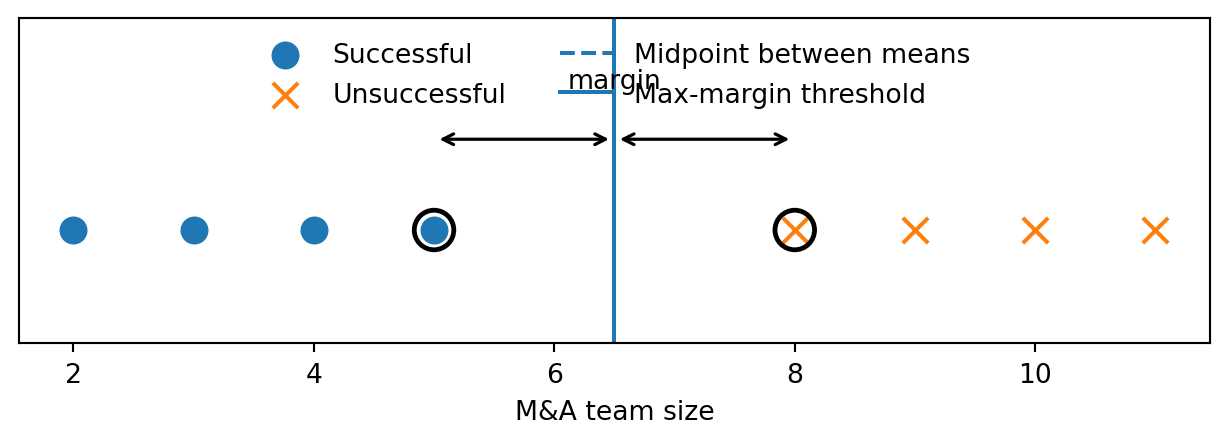
Teaching point: The midpoint between means uses the class centers. The maximal margin classifier uses the edge cases that define the safest separating threshold. This matches the standard SVM intuition that only the nearest points determine the margin.
Support vector classifier (soft margin)
Now allow slight overlap:
- one relatively small team is unsuccessful
- one relatively large team is successful
The support vector classifier keeps a central boundary, but also allows some points to lie inside the margin or even on the wrong side of the boundary.
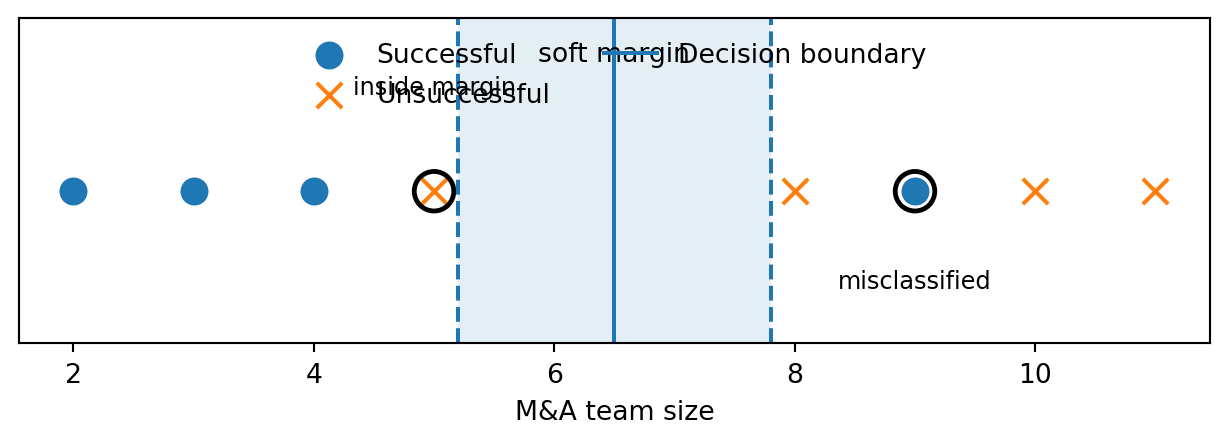
Teaching point: This is the most important soft-margin visual: one point can be inside the margin but still correctly classified, while another can be across the boundary and misclassified. That is exactly the role of slack variables in the standard support vector classifier formulation.
Support Vector Machines (Kernel trick for nonlinear patterns)
Change the M&A example. Assume:
- small → unsuccessful
- mid-sized → successful (“sweet spot”)
- large → unsuccessful
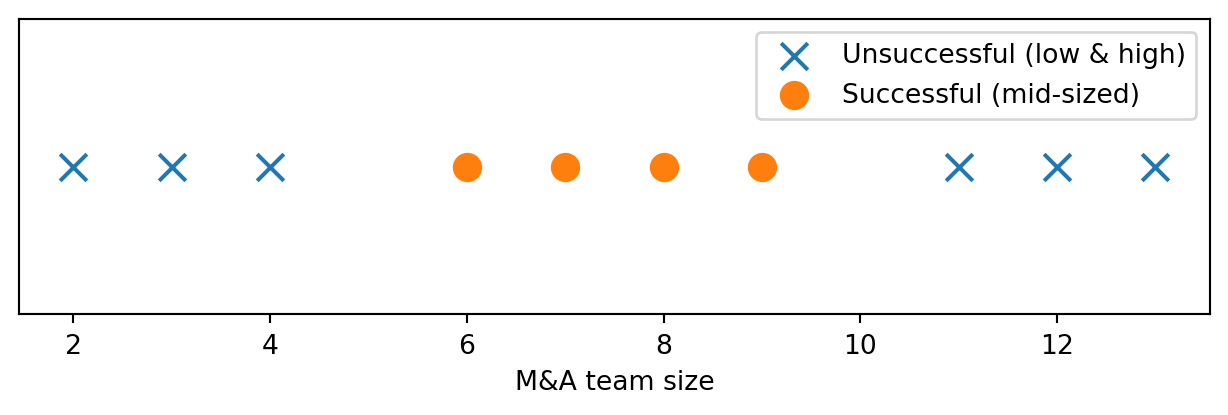
Note: linear separation no longer possible.
Transformation (Quadratic transformation)
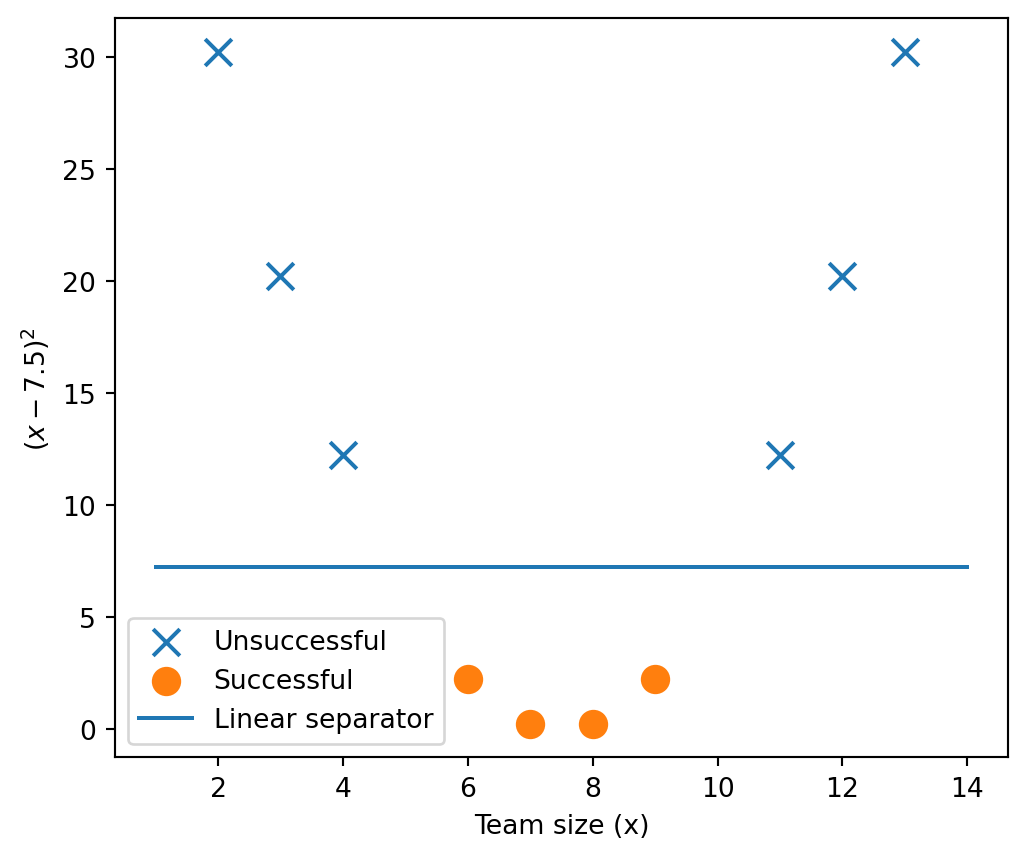
Teaching point: The kernel trick makes nonlinear patterns linearly separable in a transformed space.
Short wrap-up
- Maximal margin classifier → perfect separation
- Support vector classifier → allows some errors
- Support vector machine → handles nonlinear patterns
Exercises
2026-04-20: 80 min (Data Analytics with Python.pdf : Ridge Regression (p.57), Decision Trees and Random Forests (p.28), and Support Vector Regression (p.20))
TODO: add to exercise: If a model is trained on scaled data, it will only work with scaled data. Note, that the scaling must be exactly the same as for the training data. Thus, it is necessary, to keep the scaler.
Materials
Lectures: https://harvard-iacs.github.io/2019-CS109A/lectures/lecture15/presentation/Lecture15_Decision_Trees.pdf
https://medium.com/data-science/entropy-how-decision-trees-make-decisions-2946b9c18c8